
Research
Phoenix-1: Realistic Avatar Generation in the Wild

Written by

Christian Safka
In this post we dive into the development of generative models for realistic avatar creation and text-to-video generation. Specifically, we use audio and text driven 3D models alongside a combination of volumetric rendering techniques and 2D GANs, creating lifelike replicas from short 1–2 minute length videos.
Our groundbreaking model, Phoenix, demonstrates the capability of generating high quality full-body replicas that capture a broad spectrum of human appearance, expression, and emotion. After the replica has been trained, we use model weights and other intermediates for efficient text-to-video generation with new unseen scripts. Phoenix is robust to large diversity in voices, appearances, and video conditions. It can generate videos spanning a wide array of durations, resolutions, and aspect ratios.
This in-depth study will cover the following:
The field of avatar creation has grown significantly over the last few years, with recent innovations vastly eclipsing earlier methodologies. Current pioneering efforts are predominantly driven by the growing sophistication of 2D Generative Adversarial Networks (GANs) e.g., Wav2Lip (1), Write-a-speaker (2), and DINet (3), and the innovative 3D reconstruction and rendering techniques offered by Neural Radiance Fields (4) (NeRF) and 3D Gaussian Splatting (5) (3D-GS).
Concurrently, there are research efforts toward one-shot or few-shot avatar generation (6) that are very promising. At this time, those techniques struggle with maintaining high-fidelity output across a diverse range of input.
The goals of Phoenix are twofold - first to create a replica of the person, and second to enable real-time text-to-video generation from new scripts.
Our model can be broken down into the following stages:
Our audio engine trains multiple voice models for each avatar. It is able to detect and deploy the best version of the model to capture your accent, your range of expression, as well as sound natural with new script input.
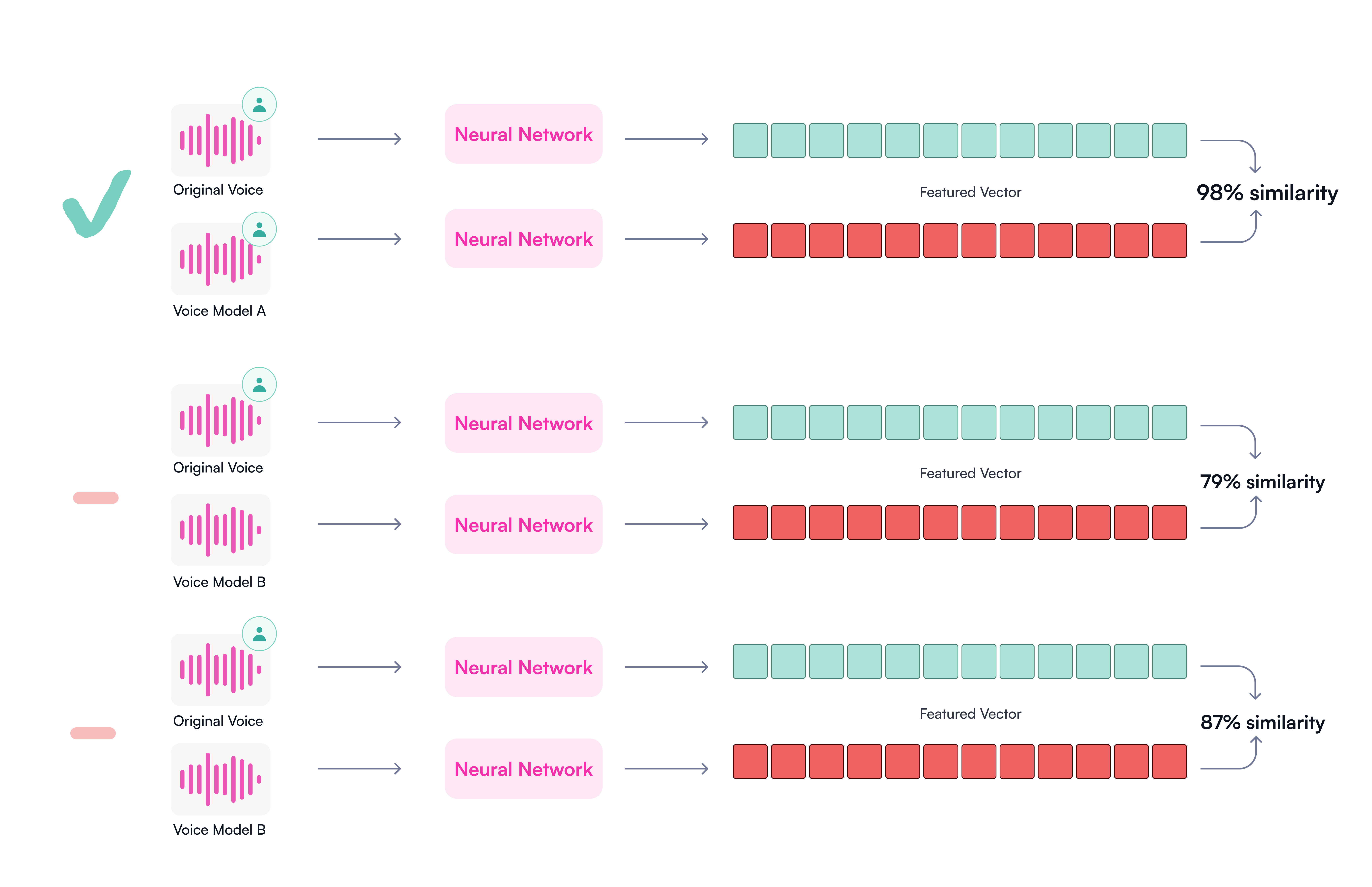
To match the voice model to the original audio, we explore the use of a speaker similarity model with encoding, distance calculation, and prediction modules trained end-to-end (See Figure 1).
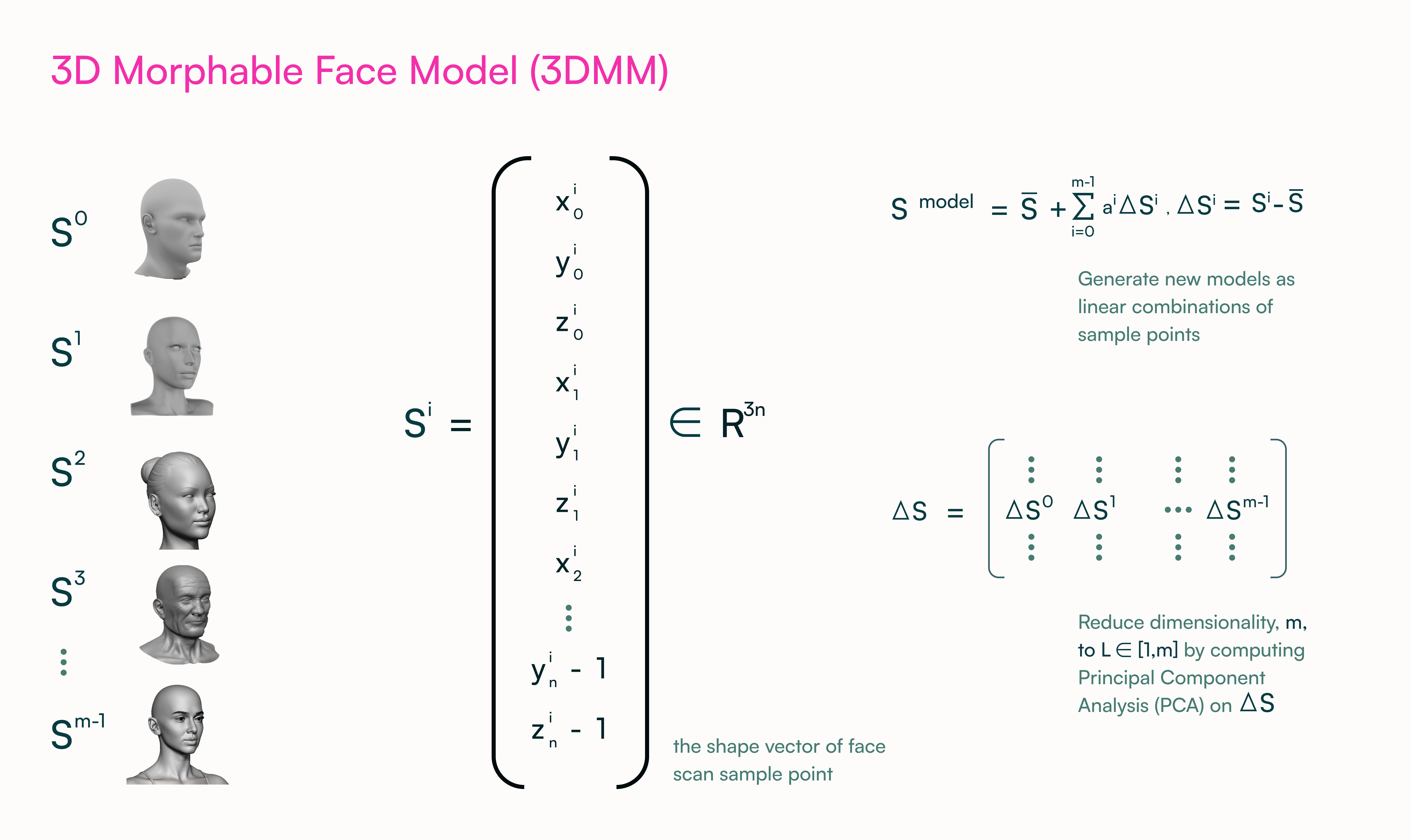
Using frames from a short video, our 3D reconstruction model observes the same person with dynamic head movements and expressions. First, we regress a 3D Morphable Model (3DMM) of the head and shoulder (See Figure 2-A and Figure 2-B for some examples from similar research work). Then we combine this model with differential rendering techniques and fine-tune the facial geometry details, learning them from thousands of 3D scans and cutting-edge implicit representations (See Figure 3 for another research example).
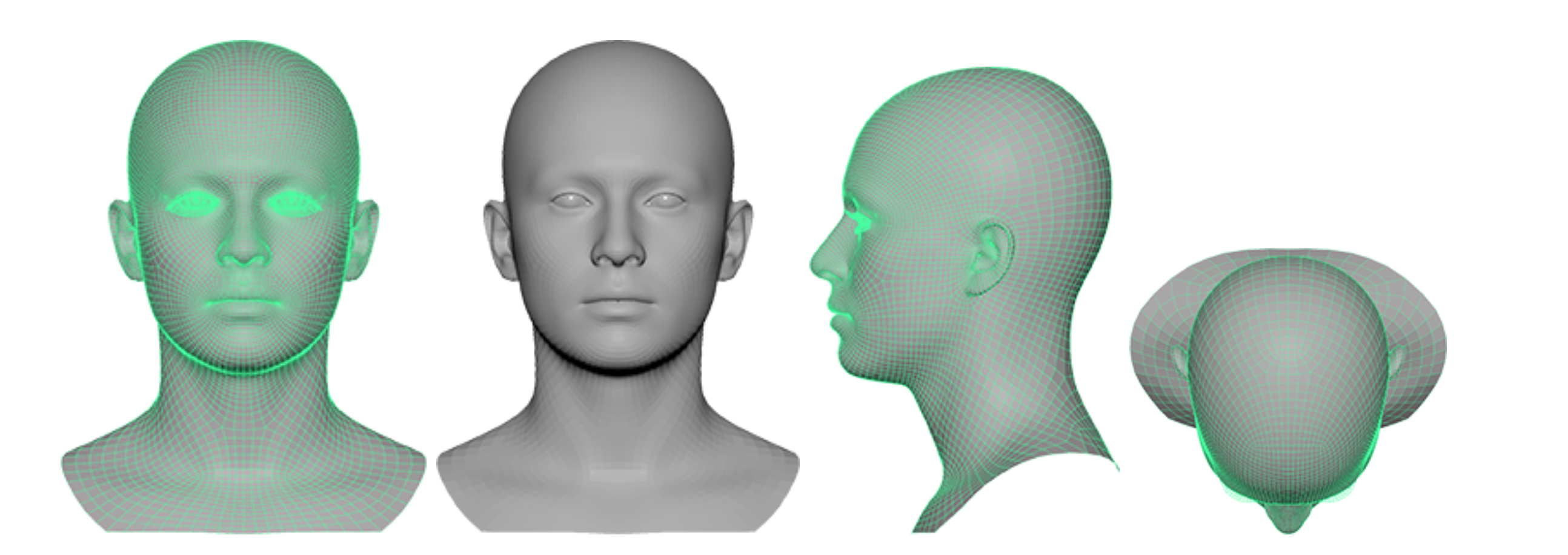

To tackle the 3D reconstruction problem, we implemented an in-house pipeline utilizing several components such as dense face landmarks, face tracking, pose estimation, identity/expression refinement, wrinkle and facial detail recovery.
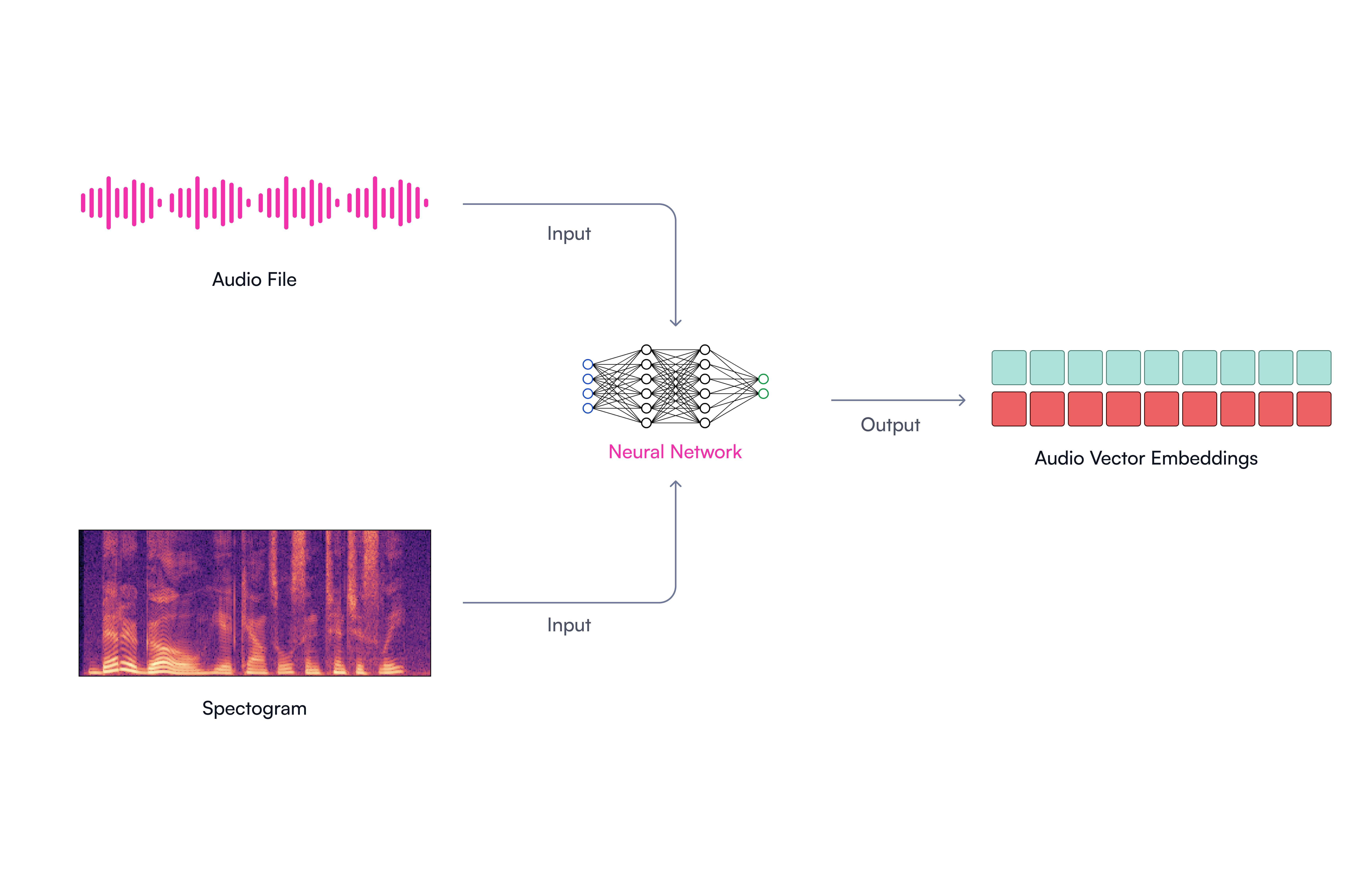
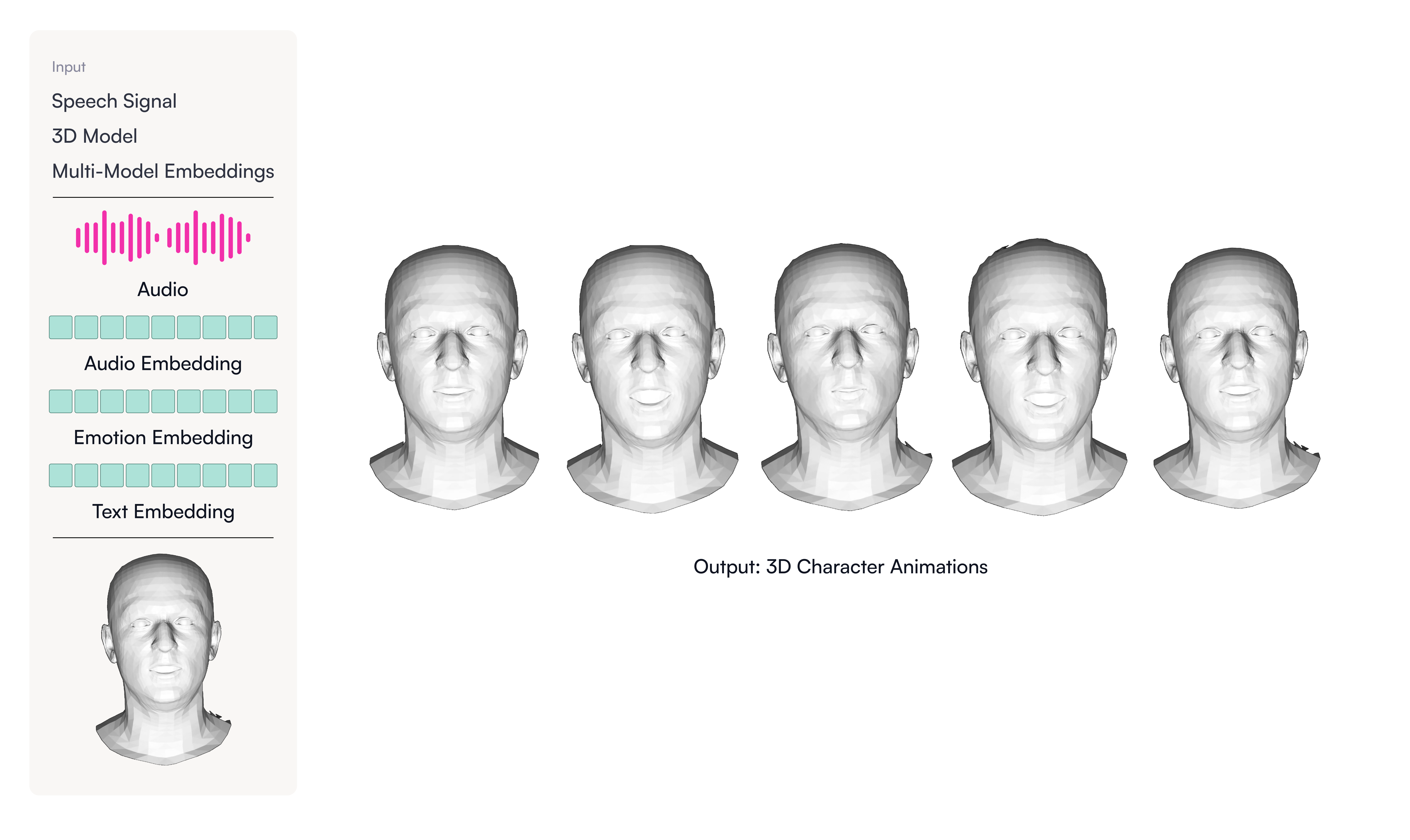
We generate audio from text-to-speech models. The audio is encoded using embedding models trained on thousands of hours of multilingual speech. We transform the audio to speech related signals and convert them into audio features like Mel-frequency cepstral coefficients (9) (MFCC). Finally, the pretrained audio embedding model will map the high-dimensional audio features into a compact latent space, in which we can evaluate the voice similarities and extract latent representations for visual model training (See Figure 4 for a visual explanation).
To build a realistic facial animation model, we compiled a large diverse in-the-wild video dataset. We train multiple foundational models on text and audio for a wide array of emotions, facial attributes and lip synchronization (See Figure 5).
Further personalizing the animation to the target, we fine-tune these models per avatar. This fine-tuning uses the raw audio, audio embeddings, and the 3D model from the previous steps as input to learn the specific speaking styles of each person.
In order to achieve high-fidelity avatar videos, we combine state-of-the-art GANs and cutting-edge implicit volumetric rendering techniques (e.g. NeRFs and 3D Gaussian Splatting) to build our video rendering pipeline.
Since traditional GANs are generally limited by the image resolution while volumetric models are struggling with the temporal consistency issue, we make significant improvements to both research categories and strategically integrate them together. By jointly optimizing these merged models, we are able to surpass the current limitations of either solution.
Finally, we have a rendered video with new animations and surface texture from the original training video.
Try it out for yourself! https://tavus.io/developer
________________________________________
References
(1) Prajwal, K. R., et al. "A lip sync expert is all you need for speech to lip generation in the wild." Proceedings of the 28th ACM international conference on multimedia. 2020.
(2) Li, Lincheng, et al. "Write-a-speaker: Text-based emotional and rhythmic talking-head generation." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. No. 3. 2021.
(3) Zhang, Zhimeng, et al. "DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video." AAAI 2023.
(4) Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.
(5) Kerbl, Bernhard, et al. "3D Gaussian Splatting for Real-Time Radiance Field Rendering." ACM Transactions on Graphics 42.4 (2023).
(6) Tian, Linrui, et al. "EMO: Emote Portrait Alive-Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions." arXiv preprint arXiv:2402.17485 (2024).
(7) Li, Ruilong, et al. "Learning formation of physically-based face attributes." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
(8) Wood, Erroll, et al. "3d face reconstruction with dense landmarks." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
(9) Mermelstein, Paul. "Distance measures for speech recognition, psychological and instrumental." Pattern recognition and artificial intelligence 116 (1976): 374-388.
