
AI, News, and Ethics
How creating Sparrow made me a better conversationalist

Written by

Brian Johnson
What I didn’t expect was how deeply it would change the way I understand and participate in conversations.
The first breakthrough came when we pivoted from Sparrow-0’s semantic analysis to Sparrow-1’s real-time prediction engine. Instead of analyzing what was said, we started predicting when someone would speak next. This shift forced me to think about conversations not as exchanges of words, but as intricate dances of timing.
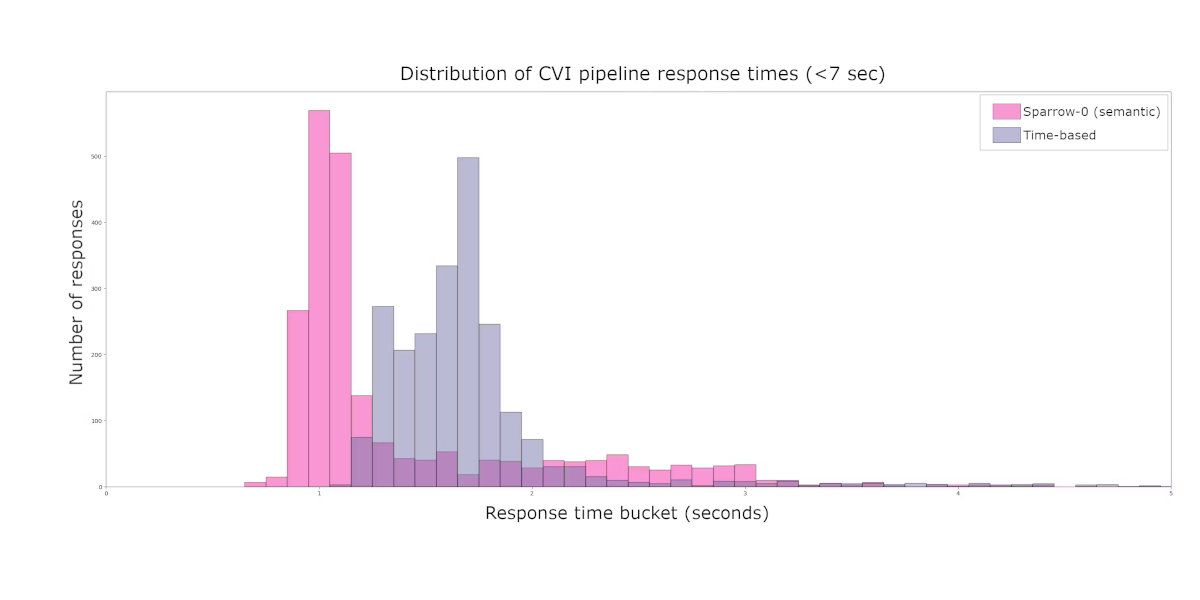
That “timing problem” was obvious in our earliest prototypes. A simple heuristic—wait ~1.3 seconds of silence, then speak—left the AI feeling either overeager or sluggish. Humans rarely let a full second drop in normal dialogue, so those pauses broke flow and eroded trust. Moving to a predictive approach meant teaching the model to anticipate turn breaks the way people do, using semantics, tone, and context instead of a stopwatch.
I began noticing patterns everywhere. That slight intake of breath before someone interjects. The way people lean forward when they’re about to speak. The subtle rhythm that emerges when a conversation is flowing well. Building a model to predict these patterns meant I had to first understand them myself.
Training Sparrow on time-to-next-speech (TTN) data revealed something profound: silence is information. A 200 ms pause might signal thinking. A 500 ms pause could mean disagreement. A 2-second pause? Someone’s probably done talking.
Back when Sparrow-0 was just a binary “done / not-done” detector, these gaps gave us a cheap training signal—we let real silence lengths become the labels. Long gaps taught the model what an end-of-turn feels like; short gaps taught it to hold its tongue. That insight transformed my own conversations. I stopped rushing to fill every silence and started reading pauses, sensing when someone was gathering thoughts versus inviting me in. My interruptions plummeted, and real understanding shot up.
Sparrow processes speech at 25 frames per second, analyzing every 40 ms window for signs of upcoming speech. That granularity taught me to notice micro-moments in conversation: the brief hesitation that signals uncertainty, the quickening pace of excitement, the steady rhythm of confidence.
Under the hood, a transformer (think BERT but streaming) turns those micro-moments into a continuous prediction of the silence about to happen. We squash that number through an inverse-sigmoid to get a confidence score—high if you’re done, low if you’re mid-thought. Exposing that threshold to developers lets a sales demo feel snappy while a tutoring app stays patient.
I found myself unconsciously adopting this high-resolution awareness in daily interactions. Conversations became richer, more nuanced. I could sense emotional undertones I’d previously missed.
One of Sparrow’s key tricks is maintaining infinite transcript context while still operating in real time. It’s the ideal conversational stance: remember everything that’s been said, yet stay fully present.
Too much focus on the past and you miss the now; too much presence and you lose the thread. Engineering that balance forced me to cultivate it personally. I learned to hold the arc of a discussion in mind while still reacting to the next sentence.
The most unexpected lesson came from implementing Sparrow’s “dual-lock” trigger. The model arms when speech is about to end (TTN < 0.2), then fires only when it sees a clear opening (TTN > 0.55). That two-step prevents false starts.
I now run a mental dual-lock in my own conversations: first sense that someone is wrapping up, then pause just long enough for the invitation. The result? Fewer awkward interruptions and much smoother turn-taking.
Perhaps the deepest change was philosophical. Creating a system that predicts human speech patterns required me to observe communication. I spent weeks combing through 100-language conversation datasets, clustering utterances so the model wouldn’t overfit on “thank you very much” loops, and labeling edge-cases where a trailing “um…” wasn’t actually the end. That analytical lens became a gift.
I became more aware of conversational dynamics: noticing when energy drops, when a new direction is needed, or when someone has something big to say but can’t find the slot.
When we lit up Sparrow-0 in production, response latency plunged from ~1.7 s to as low as 600 ms. Interruptions fell by ~50 %. User-engagement time doubled, and retention spiked 80 %. The bot suddenly felt polite. Timing, it turns out, is a massive trust signal.
Those metrics echo what I feel personally: with better timing, people relax. They stay. They forget they’re talking to code.

Sparrow-1 already predicts speech faster than humans can consciously think, but working on it has made me a better listener. Every bug we fixed, every parameter we tuned, every jitter graph we shaved taught me something about the hidden choreography of dialogue.
Next up is Sparrow-S (continuous regression) and experiments with prosody—teaching the model to read tone, pitch, and pace, not just words. We’re also exploring adaptive turn-taking so Sparrow learns your speaking style on the fly.
As we push toward Sparrow-2 and beyond, I’m excited not just about the technical possibilities but about what these models might continue teaching us about ourselves. Building Sparrow showed me that the best conversations—like the best models—balance prediction with presence, context with clarity, and timing with intention. The difference is that in conversation, unlike in code, the beauty lies not in the optimization, but in the connection.
And sometimes, that connection changes us in ways we never expected.
Get started with a free Tavus account and begin exploring the endless possibilities of CVI.
Get started
