
Research
From random noise to real images: Understanding diffusion and flow matching

Written by

Karthik Ragunath Ananda Kumar
Written by
Karthik Ragunath Ananda Kumar
Author's note: This is the first part in a series of 4 blogs explaining the diffusion and flow-matching models.
Parts 1 and 2 will focus on building the required intuition behind diffusion and flow-matching models. Parts 3 and 4 will focus more on implementing the intuitions we built in Parts 1 and 2.
Diffusion and flow-matching models form a core part of the backbone in the current SOTA image and video-generation models:
Diffusion models generate samples by initializing with noise (usually Gaussian noise) and iteratively applying a neural network to progressively map the noise into a sample in the training data distribution. In contrast, flow matching models parameterize a continuous-time map that directly pushes the initialized random noise toward the (training) data distribution in a single smooth trajectory (without stochasticity/randomness), yielding a more direct transformation.
So far, their biggest impact has been in creative media: powering tools that can produce art, photos, and video clips. However, researchers are already exploring their use in other domains, such as text generation and molecule design, demonstrating that these models aren’t limited to visuals.
Let’s first see how the images/videos are represented as data from the perspective of diffusion/flow-matching algorithms:
An image can be represented as a three-dimensional tensor: z_image ∈ R^(H × W × 3)where:
H = height (number of pixels vertically)
W = width (number of pixels horizontally)
3 = the color channels (RGB)
Each pixel is therefore a vector in R³, containing its red, green, and blue values.
A video is essentially a sequence (or stack) of image frames over time. It can be represented as a four-dimensional tensor:z_video ∈ R^(T × H × W × 3)
where:
T = number of frames (temporal dimension)
H, W, and 3 are the same as in the image case
Equivalently, a video can be thought of as:z_video = [z₁, z₂, …, z_T]with each frame:z_t ∈ R^(H × W × 3), t = 1, 2, …, TMathematically, a video is simply a sequence of stacked images indexed by time.
Suppose the prompt is: “A picture of a dog”.
These evaluations are subjective. To be more rigorous, we need to formalize criteria for what makes a generation “good.”
One way to formalize “goodness” is by asking: How likely would this image appear on the internet for the given input prompt/query — “A picture of a dog”?
Noise → impossible
Random street photo → pretty rare
Cat → unlikely (given the prompt)
Dog → very likely
This leads us to a fundamental insight:
the quality of an image ≈ the probability of how close it is to the data in training dataset.
In theory, generation simply means picking/sampling an object from the (training) data distribution:z ~ p_datawhere:z = the data object (e.g., an image, video, or text)
If we could sample directly from the data distribution, every output would look perfectly realistic. But here’s the problem: we don’t know the exact probability density function (PDF) of p_data.
i.e., We don’t have a closed-form distribution equation to model the
internet-scale images/videos, where we can simply sample from the distribution by using some parameters in a controlled / random way.
Example:
To expand a bit more on the above, since it will provide the segway on why we need generative models:
The probability density function p_data(z) tells us how likely it is to observe a data point zin the training dataset.
High value → realistic/likely
Low value → unrealistic/unlikely
It gives us a numerical measure of plausibility for every possible data object (evaluated at time t) to be present in the training dataset.
To know p_data exactly, we would need:
1. Infinite data: every possible image, video, or text sample that could exist
2. Perfect modeling: the ability to compress all of this into a single mathematical function
This is practically impossible because real-world data is too high-dimensional and complex. Even huge datasets (ImageNet, LAION, YouTube, etc.) are just approximations of the true distribution.
If we somehow knew the exact p_data:
We could generate perfect samples directly
We could evaluate quality exactly (by computing probabilities)
We wouldn’t need generative models at all
But since we don’t (which would be the case when fitting to any real-world distribution), we need a model that can learn to approximate it.
Generative models are designed to approximate the unknown data distribution.
The recipe:
1. Start with a simple, known distribution (like Gaussian noise): x ~ N(0, I_d)
2. Train a model that transforms this simple noise into samples resembling p_data: x ~ p_init → Generative Model → z ~ p_data
This is what diffusion and flow-matching models do: they provide systematic ways to approximate p_data without ever knowing it explicitly.
So far, we’ve looked at unconditional generation (just sampling any realistic object). But often we want to condition on a prompt: like “dog,” “cat,” or “white dog with black dots.”
This is modeled as a conditional distribution:z ~ p_data(· | y)where:z = the output (the generated image/video)y = the prompt or condition (text description, label, or other guiding signal)
Key distinction:z = the data we generatey = the instruction guiding what we generate
Now, let’s see in detail how we can accomplish the goals of approximating data distribution to produce a realistic images/videos in an unconditional/conditional-(prompted) way using Flow and Diffusion Models
Imagine you have a bunch of data points (like images, text, or audio) and you want to understand how they can transform from one form to another (from random/gaussian noise to the data domain — image, text, video, etc). Flow models provide a mathematical framework to describe these transformations as smooth, continuous movements through space.
Think of it like this: instead of magically teleporting from point A to point B, flow models describe the entire journey - every step along the way.
Let’s first understand the fundamental components that constitute a flow-model:
Meaning behind Notations:
x → f(x) means "x maps to f(x)"
a : [b,c] → R^d means “Function a maps each input from interval [b,c] to a d-dimensional real vector.”
a : R^d × [b,c] → R^d means “Function a takes a d-dimensional vector and a value from interval [b,c], then outputs a d-dimensional vector.A trajectory describes how a data point moves through time.
Formally, a trajectory is a function of time:
x : [0,1] → R^d
t ↦ x_tAt any given time t, the trajectory gives a vector x_t ∈ R^d.
Intuitively, you can imagine x_t as a point moving through space as time evolves.
A vector field tells us the direction and velocity of movement at every point in space and time.
Formally, we define:
u : R^d × [0,1] → R^d
(x,t) ↦ u_t(x)This means: given a point x at time t, the vector field returns a direction u_t(x) showing how the trajectory should move.
The trajectory x_t must be consistent with the vector field. This is expressed as an ODE:
dx_t / dt = u_t(x_t)This says: the velocity of the trajectory (dx_t/dt) equals the vector field evaluated at the current position.
We also need an initial condition:
x_0 = x₀which means the trajectory starts at some initial point x₀.
A flow is the collection of all trajectories that solve the ODE for different initial conditions.
Formally, we define the flow as:
Φ_t : R^d → R^d
Φ_t(x₀) = x_twhere:Φ_t(x₀) tells us the position at time t if we started at x₀.
Each initial point x₀ generates one trajectory.
Collectively, all these trajectories form the flow.
Let’s work through a simple but powerful example of a flow defined by a linear ODE.
We define the vector field as:
u_t(x) = -θx, where θ > 0This means:
If x > 0, the velocity is negative → the point moves left (toward 0).
If x < 0, the velocity is positive → the point moves right (toward 0).
No matter where we start, the vector field always points us back to the origin.
We claim that the flow is given by:
ψ_t(x₀) = exp(-θt) * x₀Here:x₀ is the initial condition (where the trajectory starts at t=0).exp(-θt) is the exponential decay factor.
This formula says: as time increases, the trajectory shrinks exponentially towards the origin.
Vector field: u_t(x) = -θx where θ > 0Proposed flow: ψ_t(x₀) = exp(-θt)x₀
We need to verify at t = 0 : ψ₀(x₀) = x₀
ψ₀(x₀) = exp(-θ·0)x₀ = exp(0)x₀ = 1·x₀ = x₀ ✓
We need to verify: d/dt ψ_t(x₀) = u_t(ψ_t(x₀))
Left side (derivative of flow):d/dt ψ_t(x₀) = d/dt[exp(-θt)x₀] = -θexp(-θt)x₀
Right side (vector field applied to flow):u_t(ψ_t(x₀)) = u_t(exp(-θt)x₀) = -θ(exp(-θt)x₀) = -θexp(-θt)x₀
Since both sides are equal, -θexp(-θt)x₀, the flow ODE is satisfied ✓
In real-world generative modeling,
The data space is high-dimensional (think: every pixel in an image frame, where each image frame is part of a stack of frames in a video).
The vector fields of the neural networks are much more complex than θx.
There’s no closed-form solution like ψ_t(x₀) = exp(-θt) * x₀.
This is why we bring in neural networks.
u_t(x) directly.Therefore, the neural network is basically going to learn to approximate the vector-field function that tells every point in the trajectory space how to move over time to match the training data distribution.
Okay, we have got a taste of high-level theoretical intuition of how flow-matching models are going to predict the vector field (velocity) of data points in random noise (P_init) and guide them towards the actual data distribution (P_data) (image/video to be generated)
Now, let’s formalize this as pseudo-code to solidify our understanding a bit more
What we have:
Starting point: X₀ ~ P_init (random noise or initial data)
Goal: X₁ ~ P_data (realistic data like images)
ODE: dX_t/dt = u_t^θ(X_t) where u_t^θ is our neural network
What we need:
A way to solve this ODE numerically
The neural network u_t^θ that gives us the right velocity at each point and time
Key insight: We parameterize the vector field u_t(x) using a neural network:u_t^θ(x) = NeuralNetwork_θ(x, t)
What this means:
Input: Current position x and current time tOutput: Velocity vector telling us which direction to move
Parameters: θ (weights and biases) that we'll learn during training
Goal: Learn θ such that following this vector field transforms noise into realistic data
Since we can’t solve the ODE analytically, we use numerical integration. The simplest method is Euler’s method.
Instead of solving the ODE continuously, we:
hneural-network to approximate this derivativeAlgorithm: Neural ODE Solver
Input: Initial point X₀, step size h, neural network u_θ
Output: Final point X₁
1) Set t = 0
2) Set step size h = 1/n (where n is number of steps)
3) Draw initial sample X₀ ~ P_init (e.g., random noise)
4) For i = 1, 2, ..., n-1 do:
X_{t+h} = X_t + h × u_t^θ(X_t)
Update t ← t + h
5) Return X₁ # (generated sample: denoised from random-noise to a sample in training data distribution - Eg: image, video, etc)Step 1: Initialize timet = 0Start at the beginning of our transformation process
Step 2: Choose step sizeh = 1/nDivide the time interval [0,1] into n equal steps
Smaller h = more accurate but slower computation
Typical values: n = 100 to n = 1000
Step 3: Sample starting pointX₀ ~ P_init (Random)For image generation: sample from Gaussian noise
For other applications: sample from the appropriate initial distribution
This becomes our “noisy” starting point
Step 4: The core iterationX_{t+h} = X_t + h × u_t^θ(X_t)This is the heart of Euler’s method
Step 5: Return resultReturn X₁
After n steps, we've traveled from t=0 to t=1 should now be a sample from our target distribution (e.g.: a realistic image)
X₁
X_{t+h}From calculus, we know:dX_t/dt ≈ (X_{t+h} - X_t)/h
From our ODE, we know:dX_t/dt = u_t^θ(X_t)
Combining these:(X_{t+h} - X_t)/h = u_t^θ(X_t)
Solving for X_{t+h}:X_{t+h} = X_t + h × u_t^θ(X_t)
Think of this as a navigation system:
Current position: X_t (Where we are now)
Ask for directions: u_t^θ(X_t) (Which way should we go?)
Choose how far to travel: h (Step size)
Take the step: X_t + h × u_t^θ(X_t) (New position)
Let’s say we’re generating a 1D-latent:
Current state: X_t = [0.3, -0.7, 0.1, ...]Neural network says: u_t^θ(X_t) = [0.1, 0.2, -0.3, ...] (how to change each pixel)
Step size: h = 0.01Next state: X_{t+0.01} = [0.301, -0.698, 0.097, ...]
Goal: Learn the parameters θ of our neural network
For each training batch:
1) Sample X₀ ~ P_init
2) Sample target X₁ ~ P_data
3) Use neural ODE solver to compute predicted X₁
4) Compute loss between the predicted and actual X₁
5) Backpropagate through the entire ODE solve
6) Update θGoal: Generate new samples
For generation:
1) Sample X₀ ~ P_init (random noise)
2) Use trained neural network u_θ in ODE solver
3) Solve ODE from t=0 to t=1
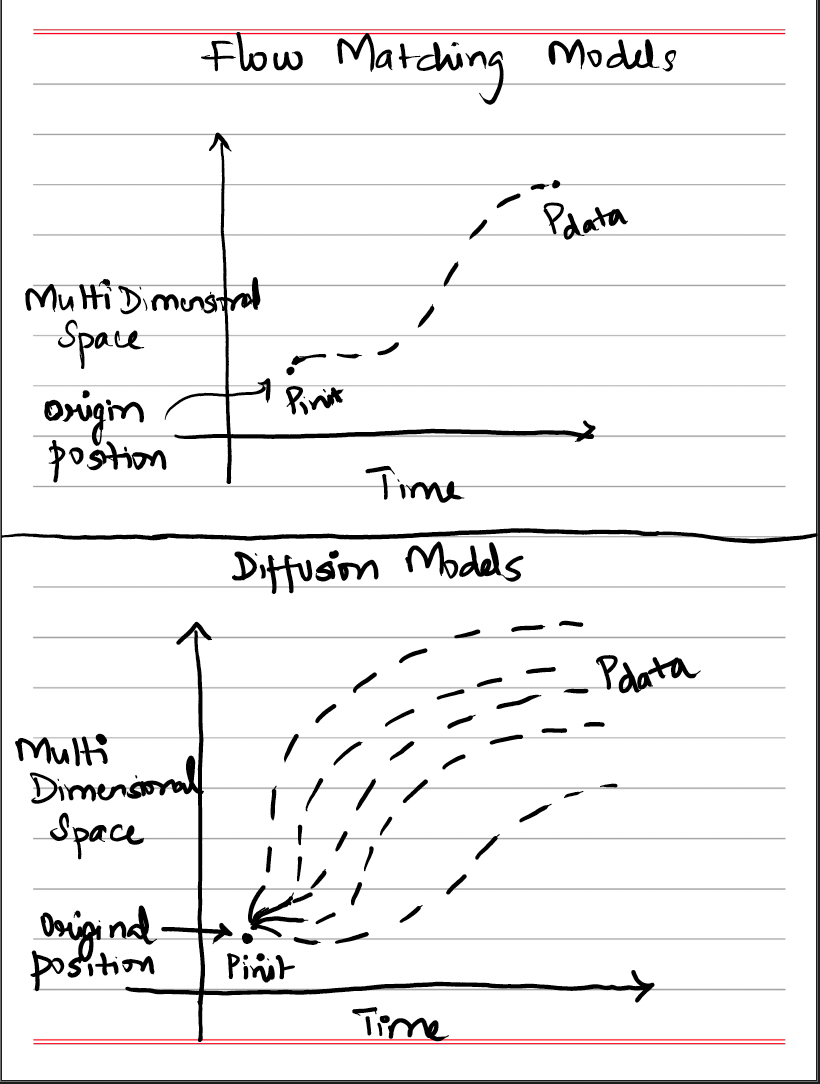
4) Return X₁ (generated sample)Now that we understand how neural ODEs work for flow models, let’s see how we can extend these ideas to diffusion models with just minor adjustments. The key insight is moving from deterministic flows to stochastic processes.
What we had (Flow Models):
Deterministic trajectories following exact paths
ODE: dX_t/dt = u_t(X_t)Given a starting point, the path is completely determined
Stochastic trajectories with randomness at each step
SDE: dX_t = u_t(X_t)dt + σ_t dW_tEven with the same starting point, we get different random paths
Neural Network Structure:u: ℝᵈ × [0,1] → ℝᵈ (x, t) ↦ u_t(x)
Breaking this down:
Input: Current position x (spatial component) + current time t (time component)
Output: Direction vector telling us how to move
Parameters: θ ∈ ℝᵏ (neural network weights that we learn)
Additional component:σ: [0,1] → ℝ t ↦ σ_t
Key insights:
Maps time t to a real number
Controls how much noise to inject at each time step
The idea of diffusion coefficient: Introduce randomness/stochasticity into our ODE
Behavior patterns:
σ large → More noise, more stochasticity
σ small → Less noise, more deterministic behavior
σ = 0 → Reduces back to our original deterministic ODE
dX_t = u_t(X_t)dt + σ_t dW_t
Initial conditions:X_0 = x_0 (Initial condition - can also be made random)
Note: “You can also make it random; let’s assume it’s fixed for now.”
Change in X_t: dX_tRepresents the infinitesimal change in our data point
This is what we’re trying to model
Drift term: u_t(X_t)dtChange due to vector field (going in the direction of the vector field)
Deterministic component learned by the neural network
Same as our original flow models
Diffusion term: σ_t dW_tInjecting some stochastic component/noise
This is what makes it a Brownian motion (also called Wiener process)
Adds controlled randomness to our system
“Brownian Motion: Random walk in continuous space and random time”
Mathematical definition:
W = (W_t) where {t≥0}: A stochastic process (collection of random variables)
Stochastic process: W = (W_t) where {t≥0}, doesn’t need to stop at t=1, can go till t
Random trajectory: Each path is different, even with the same starting point
Property 1: Always starts at zeroW_0 = 0 (Always starts at time 0, can go till ∞)Intuition: Every random walk starts from the origin
Practical meaning: The “baseline” for our randomness is zero
Property 2: Gaussian incrementsW_t - W_s ~ N(0, (t-s)I) for 0 ≤ s ≤ tKey insight: The difference between any two arbitrary time points follows a normal distribution/Gaussian distribution
Variance grows with time: Longer time intervals → more variance
t, s are two random/arbitrary time points
Property 3: Independent incrementsW_t₁ - W_t₀, W_t₂ - W_t₁, ..., W_tₙ - W_tₙ₋₁ are all independent of each otherTime points are increasing: 0 ≤ t₀ ≤ t₁ ≤ ... ≤ tₙ (time points are increasing)
Independence: What happens in one time interval doesn’t affect another
W_t ∈ ℝᵈ (can be of arbitrary dimension d)
“Brownian Motion can be drawn without lifting a pen—which intuitively means continuous motion.”
What this means:
Key insight from the diagram: Instead of one deterministic trajectory, we now have a collection of random trajectories.
u_t(X_t)
We now understand the mathematical beauty of stochastic differential equations, but there’s a crucial implementation hurdle: we can’t directly sample from a differential equation. The SDE dX_t = u_t(X_t)dt + σ_t dW_t describes continuous-time evolution, but computers work with discrete steps.
We need to transform this continuous mathematical description into a discrete algorithm that we can actually implement.
Starting from the continuous SDE: The mathematical foundation begins with our stochastic differential equation. We know that the continuous form describes the evolution of our system, but we need to find an equivalent discrete form that preserves the essential properties.
The key mathematical insight: We can derive a discrete approximation by using the fundamental definition of derivatives. From multivariable calculus, we know that:
dX_t/dt = lim(h→0) (X_{t+h} - X_t)/h = u_t(X_t)
Rearranging for practical computation: When we rearrange this equation for small but finite time steps, we get:X_{t+h} - X_t = h × u_t(X_t) + R_h(h)Where R_h(h) represents the error term that approaches zero as h gets smaller. This error term is a reminder that our discrete approximation becomes more accurate as we use smaller time steps. [To understand more about R_h(h), refer Extras Section 8.1 ].
The complete discrete form: For the stochastic case, we get the equivalent discrete form:X_{t+h} = X_t + h × u_t(X_t) + h × R_t(h)
This form now doesn’t rely on derivatives and can be directly implemented in code.
Incorporating Brownian motion: We’ve handled the deterministic part, but now we need to add the stochastic term σ_t dW_t. From our understanding of Brownian motion, we know that:W_{t+h} - W_t ~ N(0, h×I_d)
This tells us that the difference in Brownian motion over a small time interval follows a normal distribution with variance proportional to the time step.
The complete stochastic update:
Combining everything, we get:X_{t+h} = X_t + h × u_t(X_t) + σ_t(W_{t+h} - W_t) + h × R_t(h)
Simplifying for implementation: Since W_{t+h} - W_t ~ N(0, h×I_d), we can sample this difference directly:X_{t+h} = X_t + h × u_t(X_t) + σ_t × √h × εWhere ε ~ N(0, I_d) is a standard normal random variable.
Understanding the √h scaling factor is crucial for the proper implementation of stochastic differential equations. This scaling comes directly from the mathematical properties of Brownian motion.
Property of Brownian Motion
The increment of Brownian motion over an interval of length h is distributed as:W_{t+h} - W_t ~ N(0, h)
This means the increment has:
Mean: 0 (no systematic bias)
Variance: h (grows linearly with time interval)
The key implication
Since variance measures the square of the “typical size” of fluctuations, the standard deviation (the actual scale of random jumps) is:Standard deviation = √(variance) = √h
Important insight: Randomness in Brownian motion grows with the square root of elapsed time, not linearly with time. This is a fundamental property that distinguishes Brownian motion from simple linear processes.
To generate the correct increment in discrete time steps:
ΔW ≈ √h × εWhy this scaling works:
This scaling ensures the variance matches the theoretical requirement:Var(√h × ε) = h × Var(ε) = h × 1 = h ✓
The mathematical verification:
We need: Var(W_{t+h} — W_t) = h
We know: W_{t+h} — W_t = √h × ε
Therefore, Var(√h × ε) = h × Var(ε) = h × 1 = h
The scaling preserves the correct statistical properties
In code, this translates to:epsilon = torch.randn_like(x) # Sample from N(0,1)
brownian_increment = math.sqrt(h) * epsilon
This √h scaling is essential for maintaining the mathematical integrity of the stochastic process during numerical simulation.
Algorithm: Sampling from SDE (Euler Maruyama Method)
Input:
- Vector field u_t (neural network)
- Number of steps n
- Diffusion coefficient σ_t1) Set t = 0
2) Step size h = 1/n
3) X_0 = x_0 (starting condition - random noise)
4) For i = 1, ..., n-1 do:
# Draw a sample from a standard Gaussian
ε ~ N(0, I_d) # because the time steps differ by h
# Add additional noise with variance h
# scaled by diffusion coefficient σ_t
X_{t+h} = X_t + h × u_t(X_t) + σ_t × √h × ε
Update t ← t + h
5) Return X_0, X_h, X_{2h}, X_{3h}, ..., X_1
# (X1 is approximately a sample in the training data distribution)Key implementation details:
Step size considerations: The step size h = 1/n determines both accuracy and computational cost. Smaller h gives more accurate results but requires more computation.
Noise sampling: At each step, we sample ε from a standard normal distribution N(0, I_d). This is computationally efficient and maintains the independence property of Brownian motion increments.
Scaling by diffusion coefficient: The term σ_t × √h × ε properly scales the noise according to our diffusion schedule and the time step size.
The error term R_h(h) represents the difference between our discrete approximation and the true continuous solution. Let’s explore this with a concrete example.
Simple Example: Linear Growth
Consider the simple ODE:dx/dt = 2x
x(0) = 1
The exact solution is: x(t) = e^(2t)
Our discrete approximation using Euler’s method:x_{t+h} = x_t + h × (2x_t) = x_t(1 + 2h)
Comparing Exact vs. Approximate
Let’s see what happens at t = 0.1 with step size h = 0.1:
Exact solution:x(0.1) = e^(2×0.1) = e^0.2 ≈ 1.2214
Discrete approximation:x_{0.1} = x_0 × (1 + 2×0.1) = 1 × (1.2) = 1.2000
The error term:R_h(h) = True value - Approximation = 1.2214 - 1.2000 = 0.0214
How Error Decreases with Smaller Steps
Let’s try with h = 0.05 (two steps of 0.05 each):
Step 1: x_{0.05} = 1 × (1 + 2×0.05) = 1.1Step 2: x_{0.1} = 1.1 × (1 + 2×0.05) = 1.1 × 1.1 = 1.21New error: R_h(h) = 1.2214 - 1.21 = 0.0114
We began with a simple question: What does it mean to generate something realistically? Along the way, we saw how images and videos can be mathematically represented, how their quality can be formalized using probability distributions, and why the exact probability density function of real-world data is impossible to know.
This challenge is exactly where generative models step in. By starting from simple, well-understood distributions (like Gaussian noise) and learning to transform them into complex data distributions, these models allow us to approximate the true p_data.
From a practical perspective, this has given rise to tools that can generate artwork, videos, text, molecules, and beyond, reshaping how humans create and interact with information. Some examples of the video-generation models where Diffusion/Flow-Matching models form the core backbone are:
Tavus’ Phoenix-3, Google’s Veo-3, Meta’s MovieGen, etc.
Note: This is a summary of an article written on our researcher, Karthik's Medium. Follow him for the latest.
Get started with a free Tavus account and begin exploring the endless possibilities of CVI.
GET STARTED
