
Research
Learnings From Random LoRA-Finetuning Experiments On A Guided Music Synthesis Diffusion Model

Written by

Karthik Ragunath Ananda Kumar
Written by
Karthik Ragunath Ananda Kumar
After trying out ACE-Step v1.5 this weekend, an open-source diffusion model that generates full songs from text prompts: Github, I noticed something that kept bugging me. The model produces genuinely impressive music: the melodies work, the instruments sound right, and the structure makes sense. But the lyrics? sometimes garbled, mumbled, or sometimes just completely wrong. You give it a verse, and what comes out sounds like singing, except none of the words are the words you asked for.
So I just picked a random singing voice dataset from HuggingFace (only downloaded the English songs, which totalled about 7-8 GB, which is really small) on a random Friday night and ran some even more random LoRA experiments!
Here’s an example of what that sounds like - a baseline generation where the lyrics come out completely garbled:
This post is about that experiment. What I tried, what happened, what broke, and what I accidentally learned about how a 2-billion-parameter diffusion transformer processes text. None of this is production-ready. The model got worse at most things while getting better at a few others. But I learned a lot by poking at it.
Quick disclaimer before we dive in: in this post, ASR means Attention Sharpness Regularization, not Automatic Speech Recognition.
ACE-Step v1.5 is a 2-billion-parameter music generation model built on a Diffusion Transformer (DiT) architecture. You give it a text caption describing the style (“acoustic folk song with warm vocals and gentle guitar”), and lyrics marked up with structural tags ([Verse], [Chorus]), and it generates a complete song with vocals.
To understand the experiments in this post, we need to understand how the model actually works - what the lyrics go through before they influence the generated audio, and where the audio generation happens. This matters because every experiment we ran touches specific parts of this pipeline.
ACE-Step model’s architecture in the paper is given as:
Let’s delve a bit into it.
Here’s the specific path lyrics take through the model. This is important because our experiments directly affect how well this path works.
Step 1: Tokenization. The lyrics string ("[verse]\\nwalking down the morning road...") gets tokenized by Qwen3’s tokenizer into up to 512 token IDs.
Step 2: Shallow embedding. Those token IDs pass through embed_tokens - just the embedding lookup table of Qwen3-0.6B. This converts each token ID into a 1024-dimensional vector. Critically, this is not the full Qwen3 transformer - no self-attention, no contextual understanding. Each word gets embedded independently, as if the other words don’t exist.
Step 3: LyricEncoder. The raw embeddings go through an 8-layer bidirectional transformer with rotary position embeddings. This is where the lyrics first gain contextual relationships - “walking” knows it’s followed by “down” and preceded by “[verse]”. The output is projected to 2048 dimensions: [B, 512, 2048].
Step 4: Packing. The lyric embeddings (512 tokens), timbre embedding (1 token), and caption embeddings (~256 tokens) get concatenated and sorted (real tokens first, padding last) into a single packed sequence: encoder_hidden_states [B, 769, 2048].
Step 5: Cross-attention. At each of the 24 DiT layers, the audio latents being denoised (the “queries”) attend to this packed conditioning sequence (the “keys” and “values”). This is the only mechanism through which lyrics influence the generated audio. At each time position in the audio, the model computes attention weights over all 769 conditioning tokens and uses those weights to pull in the relevant information.
The cross-attention computes (simplified):
Q = W_q · audio_latent [B, T, 16 heads, 128 dim]
K = W_k · packed_conditions [B, 769, 8 heads, 128 dim]
V = W_v · packed_conditions [B, 769, 8 heads, 128 dim]
attention_weights = softmax(Q · K^T / √128) [B, heads, T, 769]
output = attention_weights · VThis is simplified. In practice, ACE-Step uses grouped-query attention (GQA) with 8 KV heads shared across 16 query heads, and the 24 self-attention layers alternate between sliding window (window=128, odd layers) and full bidirectional attention (even layers). Cross-attention is always full (no sliding window). But the core idea is the same: audio queries attend over conditioning tokens to pull in text information.
This is where the problem lives. Those attention weights have to figure out, at every moment in the audio, which of the 769 tokens to focus on. For the lyrics to come through clearly, the attention at time t (say, 2 seconds into the song) needs to focus on the specific lyric tokens being sung at that moment. Instead, the attention tends to be diffuse - spread thinly across many tokens - and the model produces something that sounds like singing but with garbled words.
Compare the two text inputs - caption vs. lyrics - and notice the asymmetry in how they’re encoded:
The caption gets the full power of a pre-trained language model. The lyrics get a much shallower encoding. This is by design (encoding 512 lyric tokens through the full 28-layer Qwen3 at every denoising step would be expensive), but it means the lyric representations entering cross-attention are less rich than the caption representations. The DiT decoder has to do more work to extract phonetic information from weaker representations.
I didn’t go into this with a sophisticated plan. The thinking was simple: the model produces garbled vocals. I have a dataset of very clean, professional singing voice recordings. What if I just LoRA-fine-tune the model on these recordings paired with descriptive prompts like “clean female alto vocals, studio recording” - would the model learn to produce cleaner vocal output in general?
That’s it. No clever alignment strategy. No carefully engineered lyrics. Just: here’s what clean singing sounds like, learn from it.
I used the English subset of GTSinger - a professional singing voice corpus with three singers (two female altos, one male tenor), five singing techniques (breathy, vibrato, glissando, mixed voice, pharyngeal, plus neutral control), and word-level phonetic annotations for every recording. All clean, studio-quality, 48kHz.
After preprocessing - filtering, deduplication, and concatenating short clips - I ended up with about 4,315 samples totaling roughly 11.7 hours of audio.
Here’s the important part that I want to be upfront about: the lyrics field for every single training sample was just [verse] - the structural tag alone, with no actual words. The preprocessing pipeline tried to extract word sequences from GTSinger’s JSON sidecar files, but the key it was looking for didn’t match the actual data format. So every sample went through with an empty lyrics field, wrapped in a [verse] tag.
What the model did get for each sample was a rich, descriptive caption:
"clean studio acapella recording, female alto vocals, breathy singing technique, neutral emotion, moderate pace, normal range, English lyrics, professional singer, high quality 48kHz recording"
And a tag-style genre prompt:
"acapella, clean vocals, female vocals, alto, breathy, English, studio recording, professional singer, neutral"
So in practice, the training data looked like this:
The model was learning to associate descriptive vocal prompts with clean singing audio - but without any word-level lyric correspondence.
I only realized this after running this experiment and going back to check the dataset - I had just given [verse] as the lyrics for every sample. That’s what makes this a genuinely random experiment. 😅
Before getting into what happened, it’s worth understanding what LoRA actually does to the architecture described above.
In each of those 24 DiT decoder layers, the self-attention and cross-attention both use four large weight matrices: W_q, W_k, W_v, and W_o (query, key, value, and output projections). These are [2048, 2048] matrices - 4 million parameters each. Normally, fine-tuning would update all of them directly. LoRA instead freezes the original weights and adds a small “side path”:
Original: output = W · x (2048 × 2048 = 4M params)
With LoRA: output = W · x + (B · A) · x (A: 2048×8, B: 8×2048 = 33K params)Matrix A projects the 2048-dim input down to rank 8, and matrix B projects it back up. The product B·A is a rank-8 update to the original weight matrix. The key insight: you’re not replacing the pre-trained knowledge in W - you’re adding a low-rank correction on top of it.
Referring back to the architecture diagram, here’s exactly where LoRA adapters sit:
Each of 24 DiT decoder layers:
Self-Attention:
W_q · audio_latent + (B_q · A_q) · audio_latent ← LoRA on Q
W_k · audio_latent + (B_k · A_k) · audio_latent ← LoRA on K
W_v · audio_latent + (B_v · A_v) · audio_latent ← LoRA on V
W_o · attn_out + (B_o · A_o) · attn_out ← LoRA on O
Cross-Attention:
W_q · audio_latent + (B_q · A_q) · audio_latent ← LoRA on Q
W_k · packed_conds + (B_k · A_k) · packed_conds ← LoRA on K
W_v · packed_conds + (B_v · A_v) · packed_conds ← LoRA on V
W_o · attn_out + (B_o · A_o) · attn_out ← LoRA on O
MLP: FROZEN (no LoRA)That’s 8 LoRA pairs per layer × 24 layers = 192 adapted weight matrices. Total trainable parameters: ~5.5M out of 2B (~0.3% of the model). The adapter file is just 22MB.
Nothing else was touched - the LM planner (Phase 1), the VAE decoder (Phase 3), the Qwen3 text encoder, the LyricEncoder, and all MLP layers in the DiT were kept frozen. The only thing being updated is the attention projections inside the DiT decoder.
Why does this matter? Look at the cross-attention LoRA adapters specifically:
So LoRA is adjusting both sides of the cross-attention conversation: what the audio asks for, and what the conditioning provides. It’s a small tweak to the communication channel between “what the model knows about the text” and “what the model is generating as audio.”
The loss converged quickly - dropping from ~0.8 to ~0.45 in the first 500 steps, then stabilizing.
I tested targeting different combinations of modules during development. Cross-attention alone produced fragmented vocal rendering - the voice would start and stop unnaturally. Self-attention alone helped temporal coherence but didn’t improve vocal quality. The combination works best. Adding MLP layers on top (tripling the parameter count to 18M) didn’t help - probably overfitting on the dataset.
I built an automated evaluation pipeline across 30 test prompts, each with a unique musical genre (folk, pop, rock, jazz, R&B, country, EDM, choral, indie, reggae, blues, synthwave, gospel, punk, bossa nova, hip-hop, lo-fi, power ballad, Latin pop, singer-songwriter, funk, lullaby, alt-rock, soul, Celtic, tropical house, grunge, disco, ambient, new wave). Each prompt had a genre-appropriate caption, tags, and four lines of original lyrics.
Note the irony: the evaluation prompts had full lyrics, but the training data didn’t. At inference time, the model receives real lyrics in the conditioning - it just never saw lyrics-paired-with-audio during fine-tuning.
For each prompt, I generated songs using the baseline model and the LoRA model with the same random seed, same parameters, same everything - the only difference was whether the LoRA adapter was loaded.
I measured two things:
Disclaimer - But just to be really upfront here, these numbers were on a really, really small sample size, sometimes just 1 sample for some genre, so they are in no way representative of the model’s capabilities. This is just a fun experiment to try out the model and see what sticks.
That’s a 23.8% relative WER reduction and a 24.7% relative CER reduction. The attention alignment also improved by about 27%.
Wait - how? The model was never shown actual lyrics during training. How did lyric intelligibility improve?
I think what happened is this: the LoRA adapter learned to produce cleaner, more articulate vocal rendering from the studio recordings. When the model then receives real lyrics at inference time (through the conditioning that was always there in the base model), the improved vocal clarity makes those lyrics more intelligible - even though the adapter itself has no concept of lyric alignment. It’s like giving someone a better microphone doesn’t change what they’re saying, but it makes the words easier to understand.
The attention alignment score improvement is more puzzling. My best guess is that clearer vocal rendering produces latent representations that are more compatible with the attention patterns the base model already learned, creating a feedback loop where better audio quality leads to slightly better attention behavior.
To be clear: these numbers are still not great in absolute terms. A WER of 46.5% means roughly half the words are wrong. But the fact that any improvement happened at all with no lyric data in training is the interesting part.
The biggest wins came in genres where the baseline either failed completely or produced heavily corrupted lyrics:
My interpretation: the LoRA adapter is doing two useful things at once in these cases. In some genres, it flips the model from degenerate/non-vocal behavior into actually singing. In others, where the model already attempts vocals, it improves articulation enough for Whisper to recover many more words.
Here’s the uncomfortable part. In several genres, the LoRA adapter made things worse:
This also makes sense in context. The LoRA adapter was trained exclusively on clean acapella studio vocals - solo singers with no instruments, no effects, no production. It biases the model toward that specific kind of output. For genres where the base model already had stable, style-specific phrasing, that bias can interfere and create regressions.
The model got better at some things by getting worse at others. This is exactly the kind of trade-off you’d expect from fine-tuning on a narrow distribution without any mechanism to preserve the original capabilities. I was okay with this going in - the point was to learn, not to ship.
The Whisper transcriptions are sometimes accidentally poetic:
The Pop result is a clean comparison. Ground truth was “I can feel the rhythm tonight / Dancing underneath the stars / Every heartbeat burning bright / Nothing in the world is ours.” The baseline produced a garbled version (“I can feel the rhythm to die …”), while the LoRA version matched all four lines exactly (WER 0.00).
To understand what the LoRA adapter is actually doing inside the model, I extracted cross-attention maps from the DiT decoder during inference and plotted them as heatmaps.
Each plot has five panels showing all model variants side by side: Baseline, LoRA (no lyrics), LoRA+ASR (no lyrics), LoRA with lyrics, and LoRA with lyrics+ASR. The first three panels relate to the Part 1 experiments discussed in this section. The last two show the Part 2 experiments (training with actual lyrics) - we analyze those panels in detail further below.

Cross-Attention Maps - Pop
A useful example. The Baseline (left) shows a visible diagonal pattern - you can see attention shifting from “I” / “can” / “feel” in the early frames to “Nothing” / “in” / “the” / “world” in the later frames. There’s also a bright horizontal band (an “attractor” token - usually a newline or structural tag - that gets attention at all time positions).
The LoRA (center) is qualitatively similar, but the distribution has shifted. The diagonal is still there but different in detail.
Baseline pop WER was 0.85, while LoRA reached 0.00 (perfect transcription on this evaluation). Despite similar-looking averaged maps, the output quality is clearly different.

Cross-Attention Maps - R&B
The Baseline (left) shows a structured pattern and produced mostly correct lyrics (WER 0.14), with minor substitutions like “Baby, sign me” instead of “Lay beside me.”
The LoRA (center) has a different pattern but collapsed in this case (WER 1.00), outputting “So So So So So.” This tells us that averaged attention heatmaps are a lossy summary - similar global structure does not guarantee usable lyrics.

Cross-Attention Maps - Jazz
The Baseline jazz attention produced reasonably good lyrics (WER 0.26). The LoRA version regressed to WER 0.42 and truncated the output earlier.
Visually subtle changes, meaningful output differences - sometimes improvements, sometimes regressions. The LoRA adapter is clearly changing how the DiT uses conditioning, but the effect is strongly genre-dependent.
After looking at the attention maps, I had an idea. One known problem with the base model is attention dilution - the cross-attention spreads too evenly across all 769 conditioning tokens instead of focusing sharply. What if I could directly penalize this during training?
Entropy measures how “spread out” a probability distribution is. A sharp distribution (most probability on one token) has low entropy. A uniform distribution has high entropy. So I added an entropy penalty to the training loss:
Total Loss = Flow Matching Loss + λ × Mean Cross-Attention EntropyThe idea: by penalizing high-entropy (diffuse) attention, the model should learn to be more “decisive” about which conditioning tokens matter at each time step.
I called this Attention Sharpness Regularization (ASR). I set λ=0.02 and retrained the LoRA adapter from scratch with this additional loss term.
It made results much worse overall. WER went from 46.5% (LoRA) to 89.2% (LoRA+ASR). The attention alignment score dropped by about 60%. The model often stopped producing coherent output.
Looking at the actual outputs across 30 genres:
Some highlights from the hallucination category:
The model frequently fell into degenerate behavior: empty output, transcript-style boilerplate, repetitive loops, or unrelated text.
No genre reached WER 0.00 in this run. The best results were Latin Pop and New Wave (both WER 0.0556), with Punk also relatively strong (WER 0.2174).
Go back and look at the rightmost panel (“Lora Asr”) in any of the four heatmap figures above.
In every single one, the LoRA+ASR attention map shows the same pattern: one or two extremely bright horizontal bands, with everything else completely dark. Every audio frame, at every point in time, attends to the exact same one or two tokens. Usually, the structural tag [Verse] or a newline character.
This is attention collapse. The entropy penalty told the model, “Be sharp - don’t spread your attention.” The model complied by finding the easiest way to minimize entropy: just always attend to the same token. One token gets all the probability mass → entropy is minimized → the regularization loss is happy.
But this is a degenerate solution. The model isn’t attending to the right token at each time - it’s attending to the same token at all times. The alignment signal is completely destroyed.
Compare this to the Baseline and LoRA panels in the same plots: their attention isn’t perfectly diagonal, but there’s temporal variation. Different frames attend to different tokens to different degrees. That imperfect, messy pattern is actually doing useful work. The ASR penalty largely removed it.
1. Cross-attention in diffusion transformers is fragile.
In language models, attention patterns are fairly robust to regularization. In a diffusion transformer, the cross-attention is the entire mechanism through which the conditioning signal (lyrics, caption, timbre) reaches the denoising process. Perturb it too much and the model loses access to its conditioning entirely.
2. “Sharp” does not mean “correct.”
The entropy penalty achieves its mathematical objective perfectly - the attention distributions become extremely sharp. But sharp attention to the wrong token is worse than diffuse attention across many tokens. Diffuse attention at least lets some correct signal leak through. Collapsed attention blocks everything except the one token it fixated on.
3. The base model’s “diffuse” attention might be a feature, not a bug.
The turbo-distilled ACE-Step model uses only 8 denoising steps (compressed from 50). With so few steps, each step has to do a lot of work. Spreading attention across multiple tokens gives the model robustness - it can average contributions from several “approximately right” tokens rather than having to nail the exactly right one every time. The entropy penalty removes this safety net.
4. λ=0.02 was probably too aggressive, but the effective range might be vanishingly small.
With λ=0.02 causing complete collapse, maybe λ=0.001 would work. But each evaluation round takes ~45 minutes (generate 30 audio clips, transcribe with Whisper, compute alignment). A proper sweep wasn’t feasible in the time I had.
5. Different layers probably need different treatment.
The entropy penalty was applied uniformly across all 24 DiT layers. But early layers probably serve different roles than deep layers. Early layers might need broad attention for global style conditioning (“this should sound like jazz”), while deep layers might benefit from sharper attention for phonetic details. A blanket penalty ignores this structure.
The most surprising result from all of this is that lyric intelligibility improved at all. The LoRA adapter was trained on audio paired with nothing but [verse] as lyrics - no words, no phonemes, no alignment signal. Yet at inference time, when given real lyrics, the adapted model produced clearer words.
This suggests something about how ACE-Step’s vocal rendering works: the quality of the phonetic output depends not just on the lyric conditioning, but on the overall quality of the vocal rendering pathway. By fine-tuning on clean studio vocals with descriptive prompts, the adapter improved the general vocal clarity of the DiT decoder. The existing (base model) lyric-to-audio alignment mechanism then worked better simply because the “audio generation” side of the equation was producing cleaner output.
It’s like the difference between a singer who knows the words but has a bad microphone, versus the same singer with a good microphone. The lyrics don’t change, but they become easier to understand.
The ASR experiment is a failure in terms of improving lyrics, but it’s one of the most informative results in the project:
Sometimes the failed experiment teaches you more than the successful one.
Note: the ablation table above comes from a separate 6-case development sweep and is not derived from eval_output_5way/results.csv.
Everything runs on a single consumer GPU. Each LoRA adapter is 22MB. Training takes about 3 hours per variant, and all four variants can be trained in parallel since they are pretty small in size.
The training runs finished. Time to see if our predictions were right.
After Part 1 revealed the empty-lyrics bug, I fixed the preprocessing pipeline to extract word-level lyrics from GTSinger’s phonetic annotations. The corrected dataset has 2,389 clips - every training sample now pairs the audio with real, properly formatted lyrics:
[verse]
there's a river full of memory sleep my darling safe and soundEach .wav file has a corresponding .txt with the actual words being sung. The captions and genre tags remained unchanged - the only difference is the lyrics field going from [verse] (empty) to [verse]\\nactual words being sung....
Before looking at numbers, it’s worth understanding what changes structurally when the lyrics field is no longer empty. Refer back to the architecture diagram from Part 1.
Part 1 (no lyrics): Every training sample had lyrics = "[verse]". The LyricEncoder processed a near-empty input - only the first few tokens ([, verse, ], \\n) had meaningful content, the rest were padding. When the Condition Encoder packed everything into the 769-token sequence, the lyric portion was essentially a block of padding with a few tag tokens at the front.
Part 1 - What the cross-attention sees during training:
Packed conditioning [769 tokens]:
┌─────────────────────┬───┬─────────────────────────────────┐
│ Lyric tokens (~512) │ T │ Caption tokens (~256) │
│ [verse] \n PAD PAD │ i │ "clean female alto vocals, │
│ PAD PAD PAD PAD ... │ m │ breathy singing technique..." │
│ PAD PAD PAD PAD ... │ b │ │
│ (almost all padding)│ r │ (rich, descriptive content) │
└─────────────────────┴───┴─────────────────────────────────┘
↑
Cross-attention learns to mostly
ignore the lyric tokens (padding)
and focus on the caption tokensThe LoRA adapters on the cross-attention K and V projections learned to represent these near-empty lyric tokens in a way that supported cleaner vocal rendering, because the audio was clean studio vocals and the caption described clean vocals. But the LoRA had no reason to learn anything about word-level content.
Part 2 (with lyrics): Now every sample has lyrics = "[verse]\\nwaking up i see that everything is okay...". The LyricEncoder processes a sequence where ~20-50 tokens are real words, and the attention mask tells the model which tokens carry content.
Part 2 - What the cross-attention sees during training:
Packed conditioning [769 tokens]:
┌──────────────────────────────┬───┬──────────────────────────┐
│ Lyric tokens (~512) │ T │ Caption tokens (~256) │
│ [verse] \n waking up i see │ i │ "clean female alto │
│ that everything is okay PAD │ m │ vocals, breathy singing │
│ PAD PAD PAD PAD ... │ b │ technique..." │
│ (real words + padding) │ r │ │
└──────────────────────────────┴───┴──────────────────────────┘
↑
Cross-attention must now learn to
attend to the RIGHT lyric tokens
at the RIGHT time - flow matching
loss penalizes misalignment implicitlyThis changes the learning signal fundamentally:
We predicted:
Time to see how wrong (and right) we were.
I ran two new training configurations on the corrected data - LoRA with lyrics (rank 8, alpha 16, lr 1e-4, 55 epochs) and LoRA with lyrics + ASR (λ=0.02, 55 epochs) - then re-evaluated all five models across the same 30-genre test set under identical conditions (same prompts, same random seeds) for a fair comparison.
All five models were evaluated on 30 genres with identical random seeds for fair comparison from the same eval_output_5way run used above.
First reaction: adding real lyrics to training barely changed the average WER. LoRA with lyrics (47.14%) sits within 1 percentage point of LoRA without lyrics (46.51%). The CER improved by about 1 point (38.06% vs 39.08%). Not exactly the dramatic improvement we predicted.
But hold on - before declaring the experiment a wash, let’s look at where those averages come from.
The averages are hiding something important. When you break down per-genre results, the two LoRA models are clearly complementary: no-lyrics LoRA has 10 unique wins, while lyrics-trained LoRA has 8 unique wins (plus 3 ties), and they are often strong on different genres.
Where lyrics training rescued previously failed generations:
These are genres where the Part 1 LoRA either failed outright (silence/instrumental/degenerate output) or underperformed. The lyrics-trained model rescued many of them. Soul improved from WER 0.28 to literally perfect (0.00). Disco went from complete silence to a recognizable dance track with nearly all lyrics correct.
Where lyrics training broke what was working:
The rock result is worth highlighting. The no-lyrics LoRA produced reasonably clear singing: “Standing on the edge of town, Staring for the sun to rise, Holding on to what is mine, Staring for the open sky” - WER 0.17, minor word substitutions, but clearly the right lyrics. The lyrics-trained LoRA produced “CBD Black Bloomberg Sour Full Appearance” - complete gibberish with no meaningful overlap. Same genre, same prompt, same seed, different adapter.
This complementary behavior has a satisfying explanation if you think back to what each adapter learned during training.
LoRA (no lyrics) was trained on clean studio vocals with [verse] as lyrics. The cross-attention LoRA adapters learned to extract vocal quality information from the caption (“clean female alto vocals, breathy singing technique…”) and project it into better vocal rendering. At inference time, when given real lyrics, the improved vocal rendering helps the base model’s existing (imperfect) lyric alignment work better. Think of it as upgrading the microphone - the singer already knows the words, you just made them clearer.
This approach succeeds in genres where the base model already has some vocal rendering capability that just needs to be cleaner: folk, pop, rock, synthwave, and bossa nova. It fails in genres where the base model’s vocal rendering is fundamentally broken - the model never attempts vocals in the first place.
LoRA (with lyrics) was trained on the same audio with real lyrics aligned to each recording. The cross-attention LoRA adapters learned something different: the K and V projections learned to represent word tokens as keys and values that carry phonetic information; the Q projections learned to formulate queries that match audio time positions to corresponding lyric tokens. The flow matching loss provided implicit alignment supervision.
This approach succeeds in genres where the base model’s vocal rendering was so broken it produced silence or degenerate output. The lyric alignment provides an additional activation signal - the model learned that “when there are real words in the lyrics, you should sing them.” This is exactly the capability the no-lyrics adapter never acquired.
It fails in genres where the no-lyrics adapter had already found a good solution, because the lyrics training introduces a different bias that can conflict with genre-appropriate vocal styling.
Think of it this way:
Neither is strictly better. They’re optimizing for different aspects of the same problem.
Tallying which model achieves the lowest WER for each of the 30 genres:
No single model wins everywhere. If you could pick the best adapter per genre, the hypothetical “oracle ensemble” would likely outperform any individual model. This suggests the path forward isn’t “one LoRA to rule them all” but rather a mixture or routing system that selects the right adapter based on genre characteristics.
Some of the most revealing side-by-side comparisons across all five models:
Soul - The Perfect Score
Ground truth: “Take my hand and walk with me / Down the road we used to know / Every river meets the sea / Every seed will start to grow”
A clean progression from silence → partial → perfect. The lyrics-trained model nailed every word. Even the ASR variant got close.
Ground truth: “Burning down the walls tonight / Nothing left for us to lose / Standing up to join the fight / We will never pay our dues”
The LoRA (no lyrics) model achieved a perfect score on the evaluation seed (43). To sanity-check this, I ran three additional seeds (44, 45, 46) - two were also perfect, one had minor substitutions. The mean WER across four seeds was 0.075, so the strong result is real but not universally zero. The lyrics+ASR variant produced severe hallucination - WER exceeding 2.0 means it generated more than twice the words in the ground truth, none of them correct: “Like and thinning will be fine / Dog and dog’s in line / Chin-na-ta-tine / Lines on your door / Turn it this time / First off, every happy, happy day…” - a much longer, off-target transcript than the original lyrics. The sharp attention penalty locked the model into lyric tokens but it couldn’t decode them, so it kept generating incorrect text.
Remember, in Part 1, attention sharpness regularization (ASR) with no lyrics was our worst failure - WER rose to 89%, the model often generated repetitive outro-like text instead of proper lyrics, and the attention collapsed to single tokens. We hypothesized that ASR failed partly because there were no real lyrics to align to.
The results partially confirm this hypothesis.
The with-lyrics ASR model is still worse than the simpler LoRA variants on average WER, but it’s no longer a total collapse. More importantly, it achieves the highest attention alignment score of any model (0.166) - its cross-attention patterns are more structured and temporally organized than any other variant, including the baseline.
Here’s what the attention metrics from the deep-analysis pipeline reveal:
Lyric Mass = fraction of cross-attention going to lyric tokens vs. caption/timbre tokens. Entropy = how spread the attention is across tokens (lower = sharper). Data from the deep-analysis pipeline using lyric-only renormalization.
The lora+lyrics+ASR variant devotes 72-84% of its cross-attention to lyric tokens - substantially more than any other model (30-64%). And its entropy is consistently the lowest, meaning its attention is the sharpest. The ASR penalty with real lyrics causes the model to:
This produces the best attention alignment scores - but not the best WER. The model is doing a great job of looking at the right lyric tokens at the right time, but a poor job of turning that attention into correct phonemes. The value projections (V) and output projections (O) - which determine what information gets extracted from the attended tokens - apparently need more training to learn effective phonetic rendering under the aggressive ASR penalty.
It’s like a student who learned to look at the right page in the textbook at the right time, but hasn’t yet learned to read the words on the page. The attention is well-aligned; the decoding isn’t.
The cases where it DOES work (punk at WER 0.04, indie at 0.05, tropical house at 0.15) tend to be genres with clear, rhythmic vocal delivery where the phonetic mapping is simpler. The cases where it fails badly (pop at WER 2.10) tend to be genres requiring more melodic, flowing vocals, where the rigid attention pattern fights against the music’s natural phrasing.
Putting the four LoRA variants in a 2×2 grid reveals the cleanest controlled experiment in this project:
Without lyrics, ASR causes attention collapse - the model attends to padding tokens because that’s the cheapest way to minimize entropy. With lyrics, ASR forces the model to attend sharply to real word tokens, which is actually useful - but λ=0.02 is still too aggressive for general use.
The key insight: entropy regularization on cross-attention is not inherently bad, but it requires meaningful conditioning content. You can’t force the model to “pay attention” when there’s nothing meaningful to attend to.
The summary heatmaps average attention across all 24 layers and all 16 query heads (8 KV heads in the GQA scheme). As the R&B analysis hinted earlier - where a simpler-looking attention pattern produced better lyrics than a more structured one - that averaging hides important structure.
To dig deeper, we generated per-head attention maps for all five model variants across four genres (folk, pop, jazz, R&B) using the improved deep-analysis pipeline. This pipeline uses deterministic extraction at the schedule-consistent timestep, lyric-only renormalization to isolate the lyric-audio relationship, and shared color scales for fair comparison across variants.
Baseline:
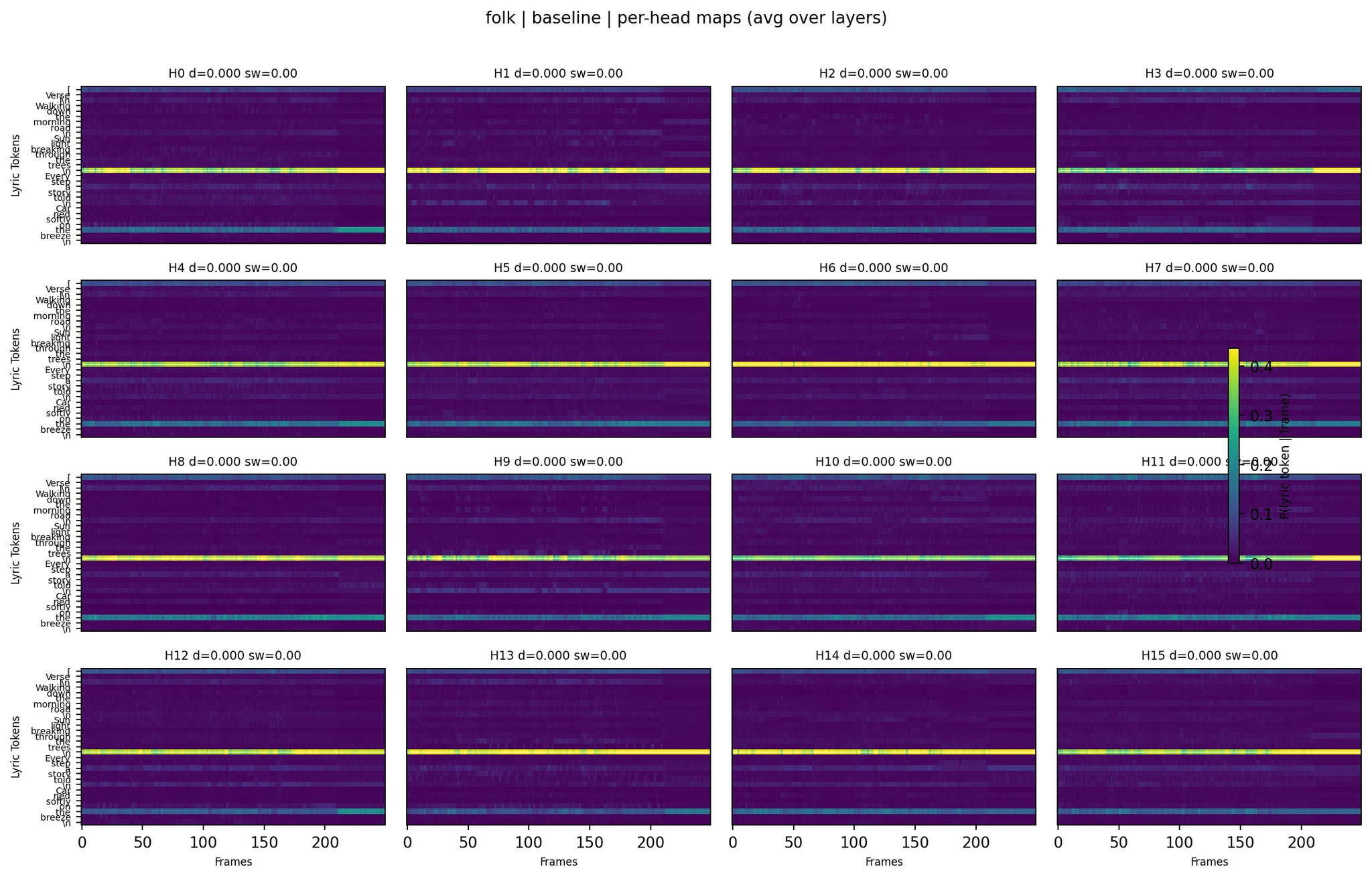
Per-Head Attention - Folk Baseline
LoRA (no lyrics):
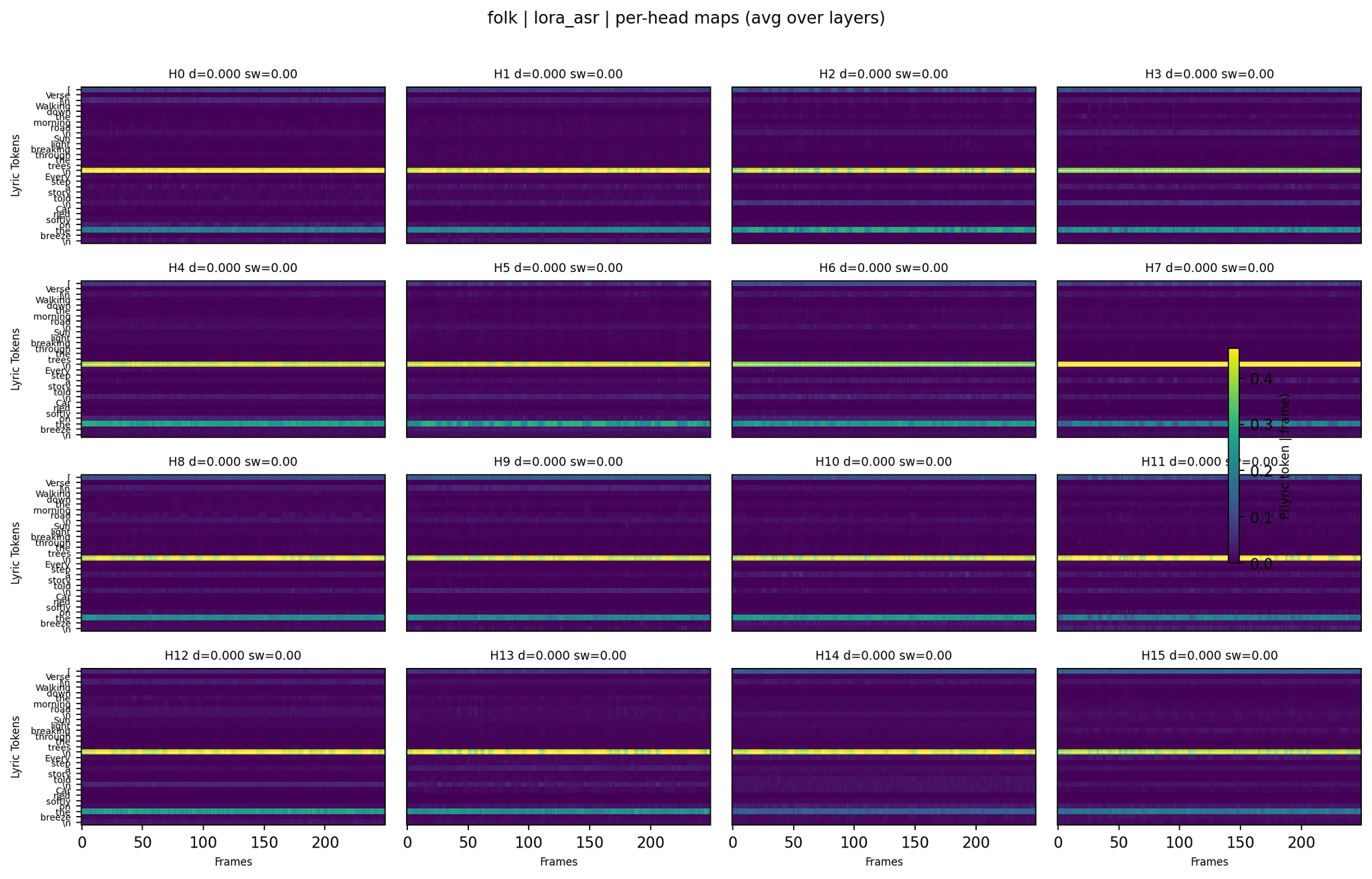
Per-Head Attention - Folk LoRA+ASR
LoRA with lyrics:
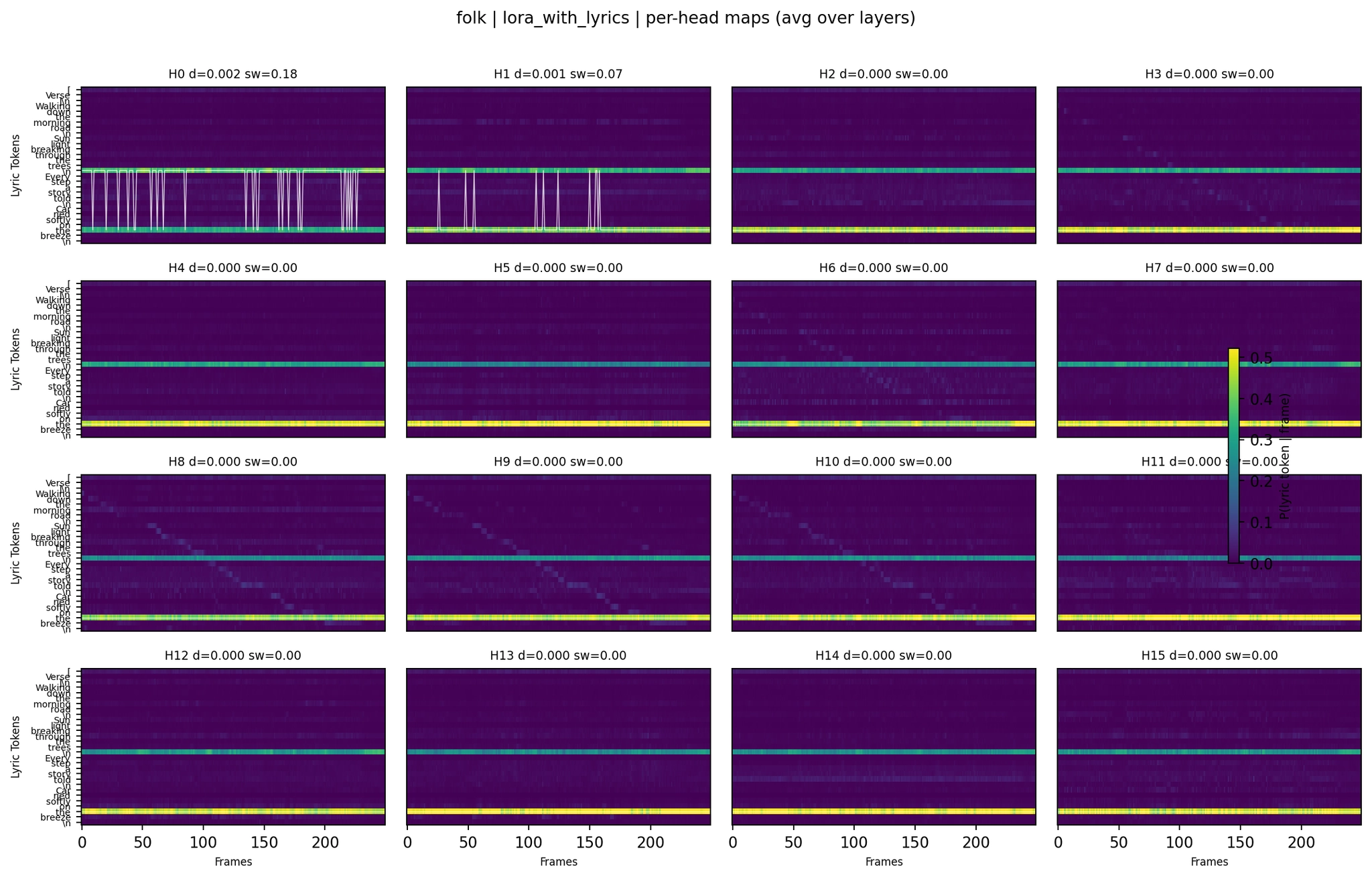
Per-Head Attention - Folk LoRA with Lyrics
LoRA with lyrics+ASR:
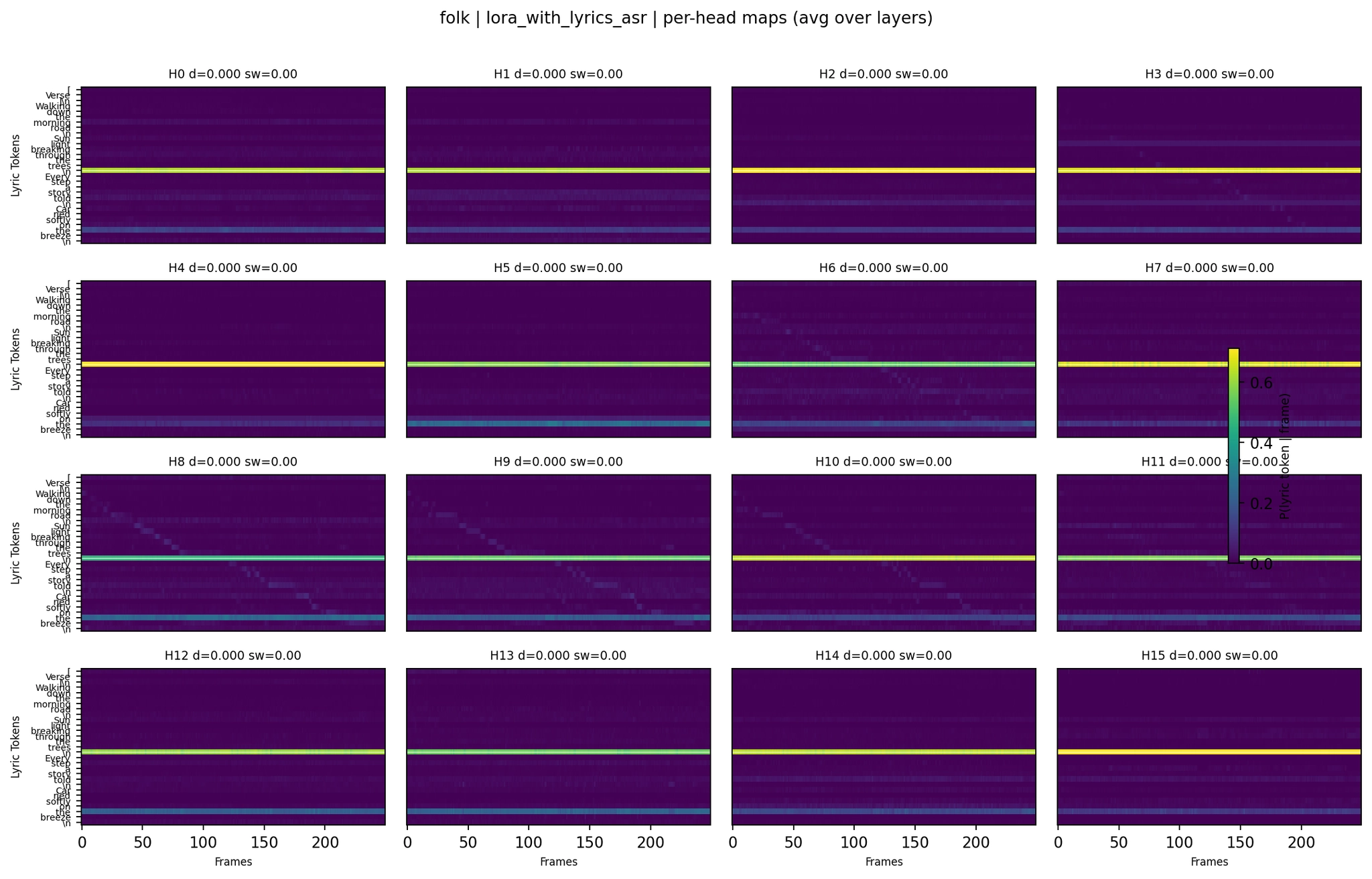
Per-Head Attention - Folk LoRA with Lyrics+ASR
Even per-head (averaged across 24 layers), most heads show a single dominant horizontal band - one token capturing most of the attention at all time positions. This is consistent across all five model variants. Tokens like \\n, [, or high-frequency words like “the” act as attention sinks that absorb probability mass regardless of audio position.
But the subtle differences between variants matter. The LoRA with lyrics folk per-head map shows slightly more variation in band structure compared to the no-lyrics LoRA - some heads have multiple bands or show transitions between tokens. The ASR+lyrics variant shows the most extreme concentration: nearly all probability mass in a few very sharp bands, consistent with its much higher lyric mass (0.84) and lower entropy (0.48).
Baseline:
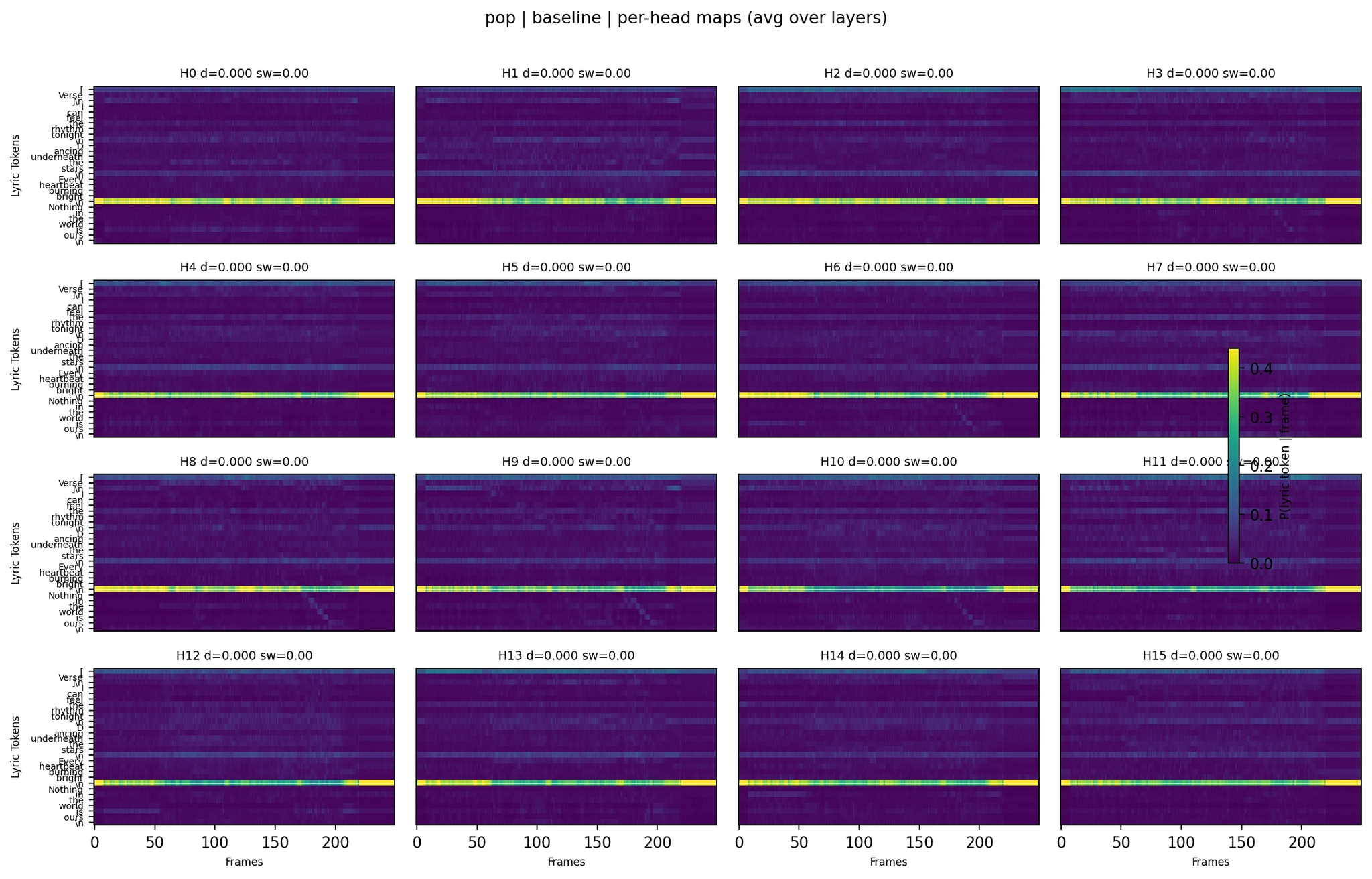
Per-Head Attention - Pop Baseline
LoRA (no lyrics) (WER 0.00 on the evaluation seed; mean 0.075 across 4 seeds - consistently strong):
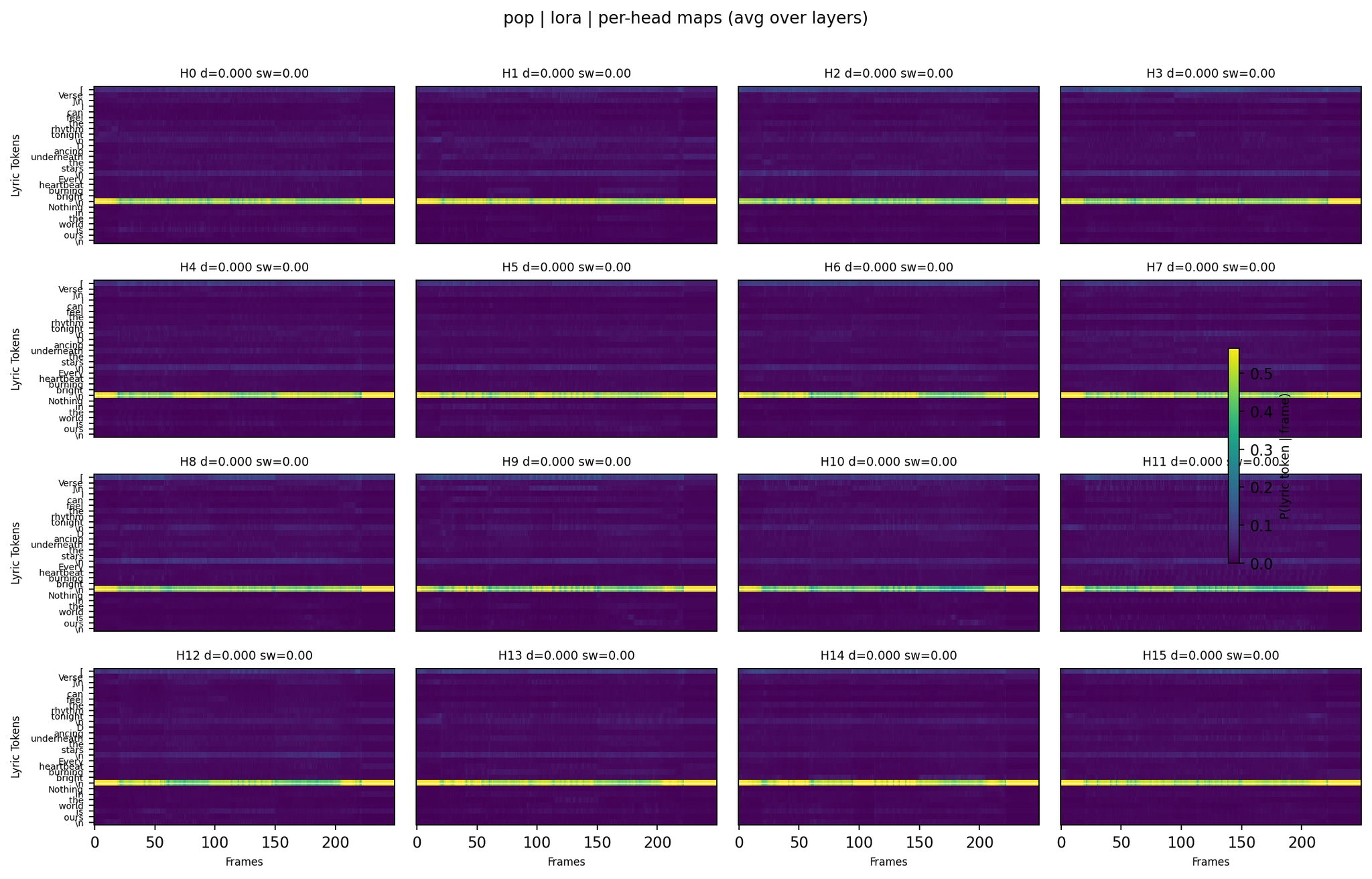
Per-Head Attention - Pop LoRA
LoRA with lyrics:
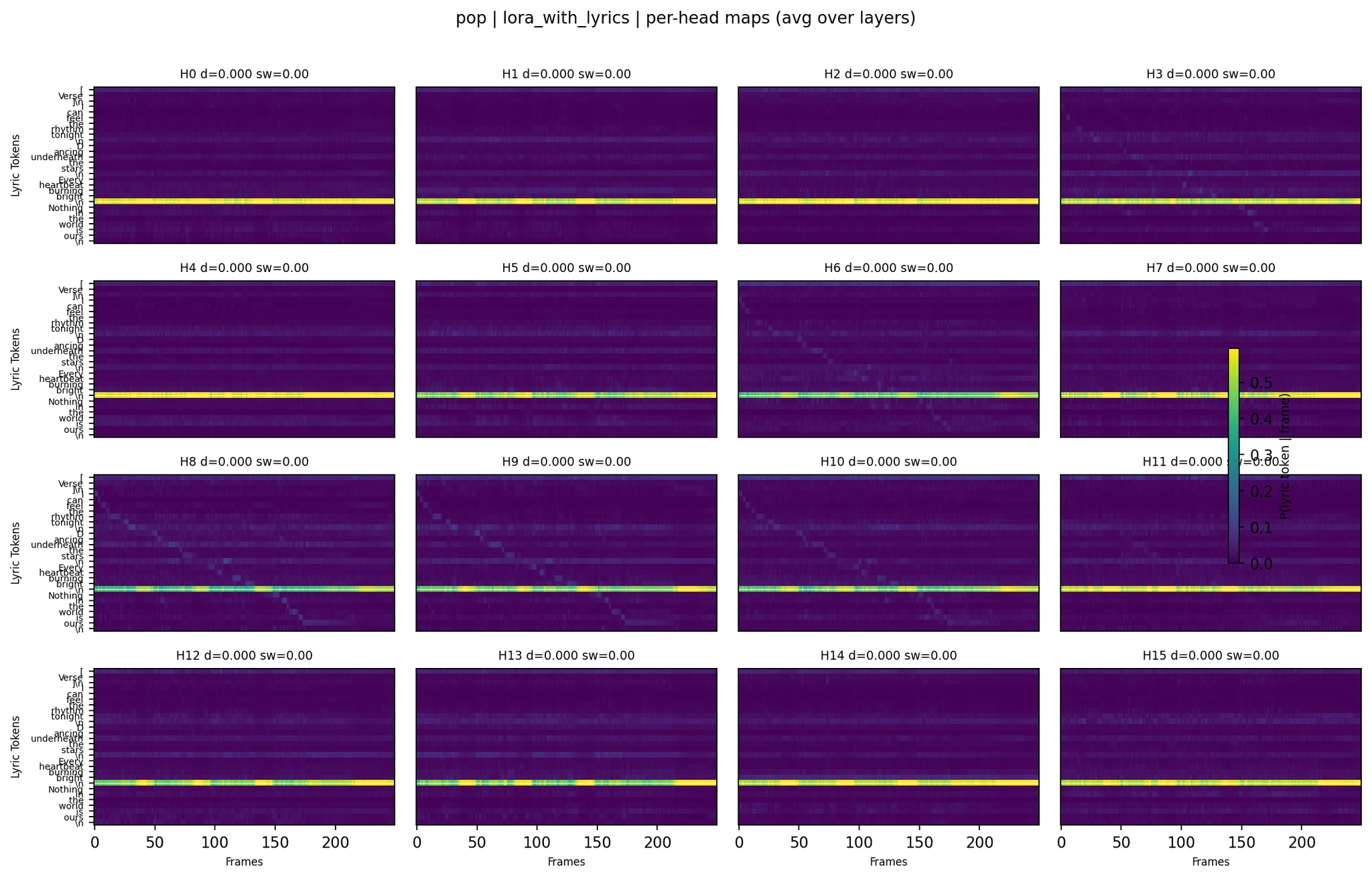
Per-Head Attention - Pop LoRA with Lyrics
LoRA with lyrics+ASR (WER 2.10 - severe hallucination):
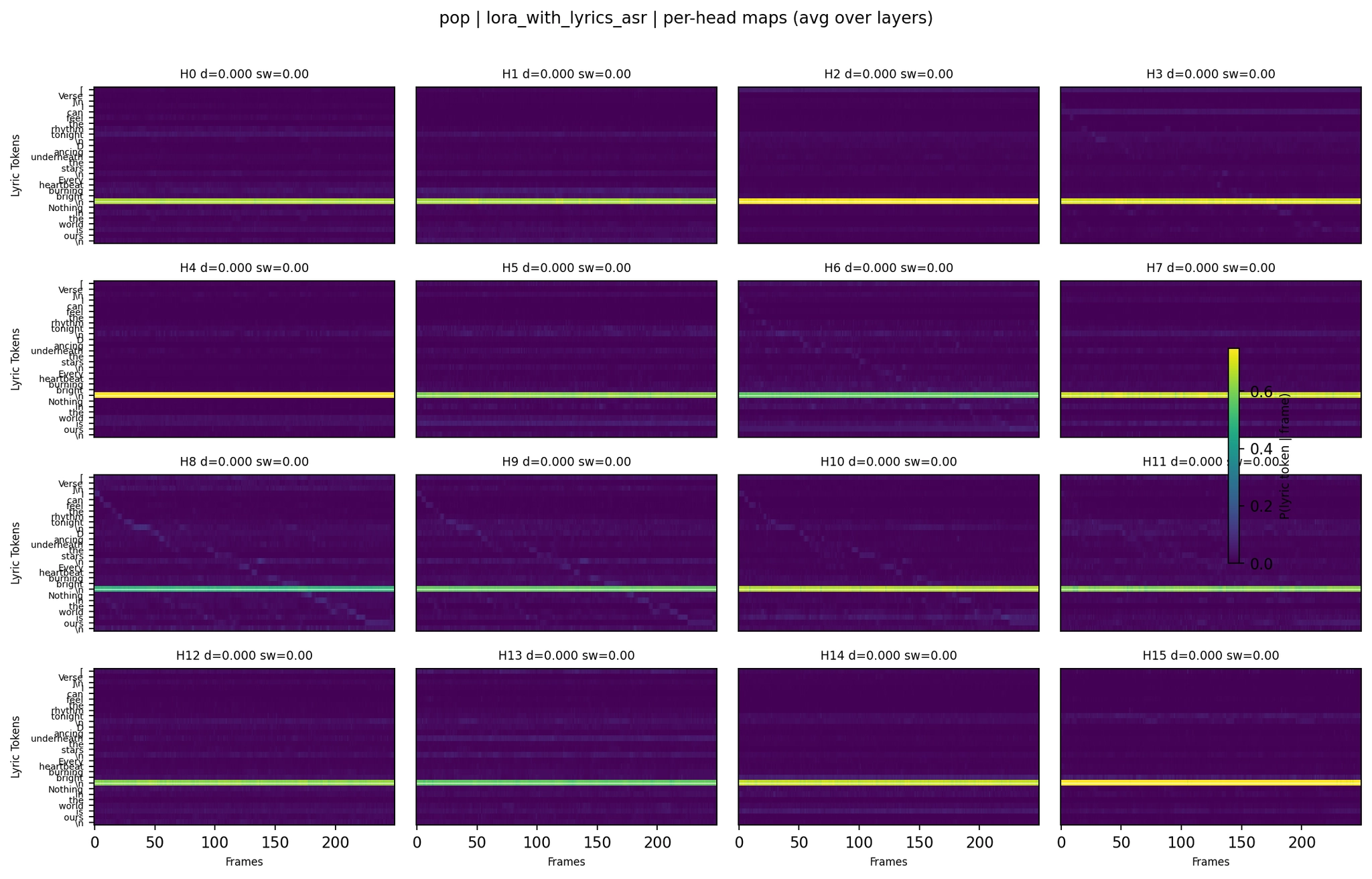
Per-Head Attention - Pop LoRA with Lyrics+ASR
The pop per-head maps show a clear progression. The LoRA variant (WER 0.00 on the eval seed, mean 0.075 across 4 seeds) shows structured head behavior - a few heads carry temporal patterns while others stay collapsed. The lyrics+ASR variant, which hallucinated heavily, shows the extreme version: attention mass concentrated in sharp bands with barely any temporal variation. The model was attending strongly to lyric tokens but couldn’t decode them.
Jazz Baseline:
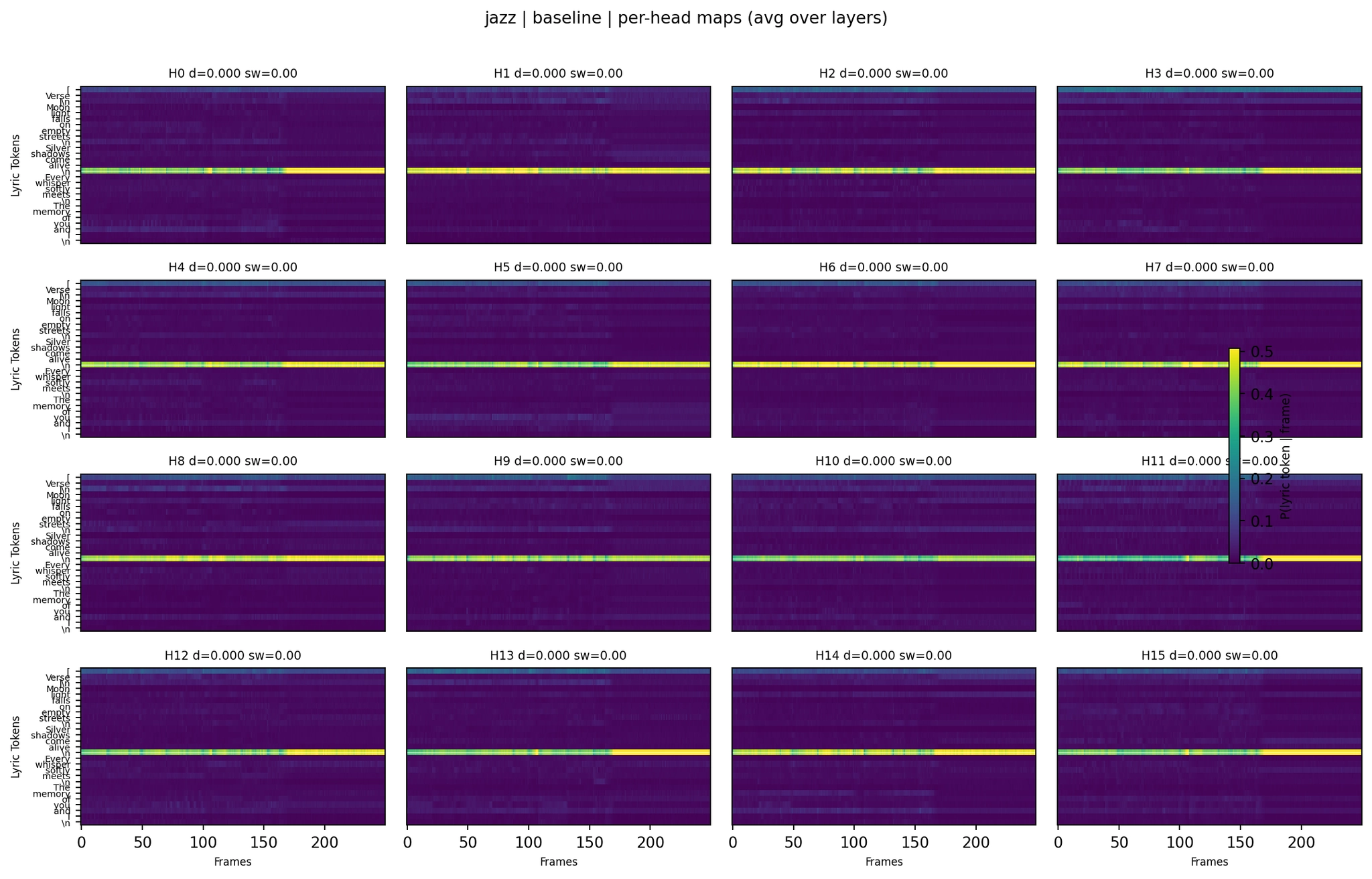
Per-Head Attention - Jazz Baseline
Jazz LoRA with Lyrics:
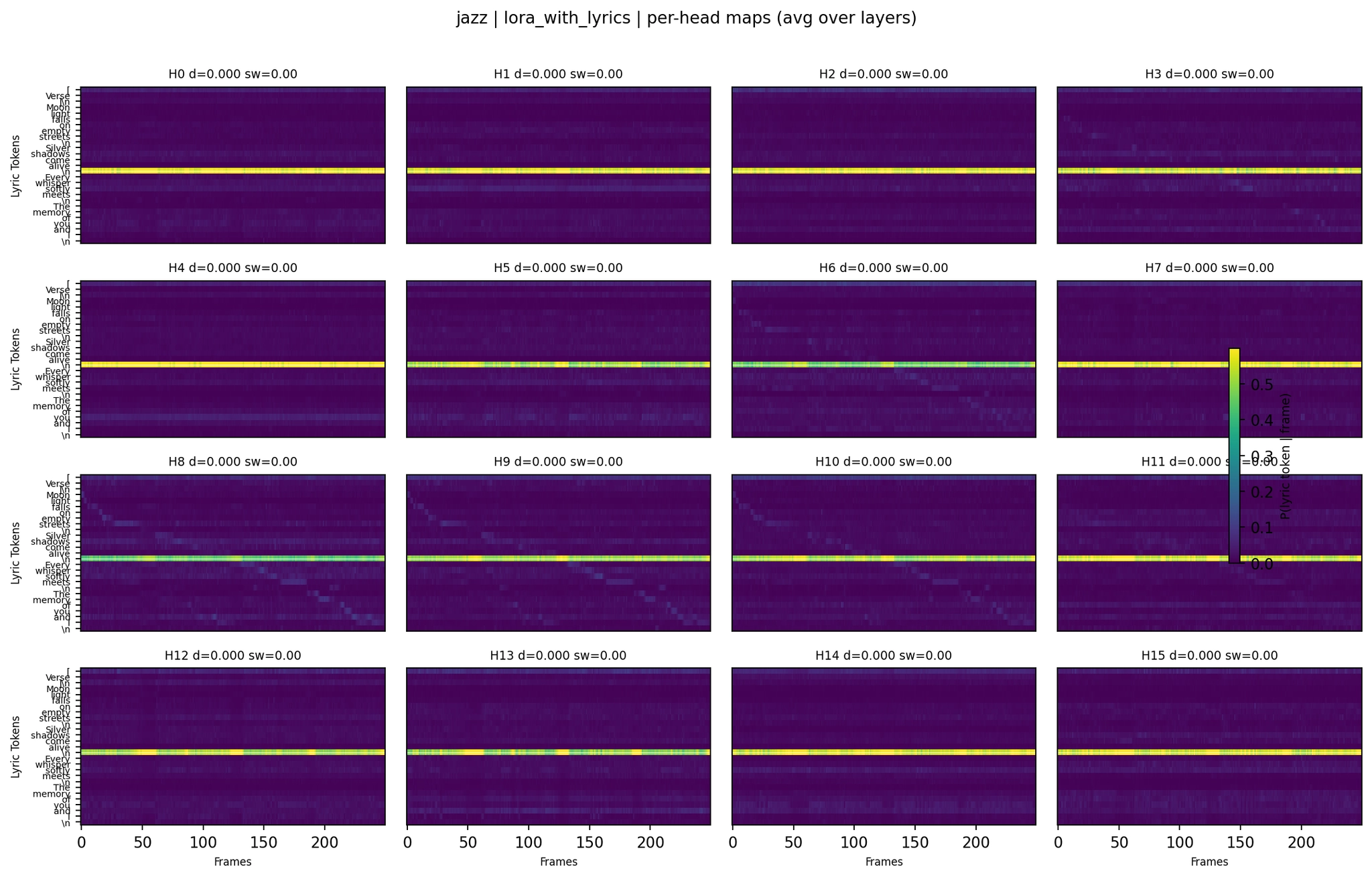
Per-Head Attention - Jazz LoRA with Lyrics
R&B Baseline:
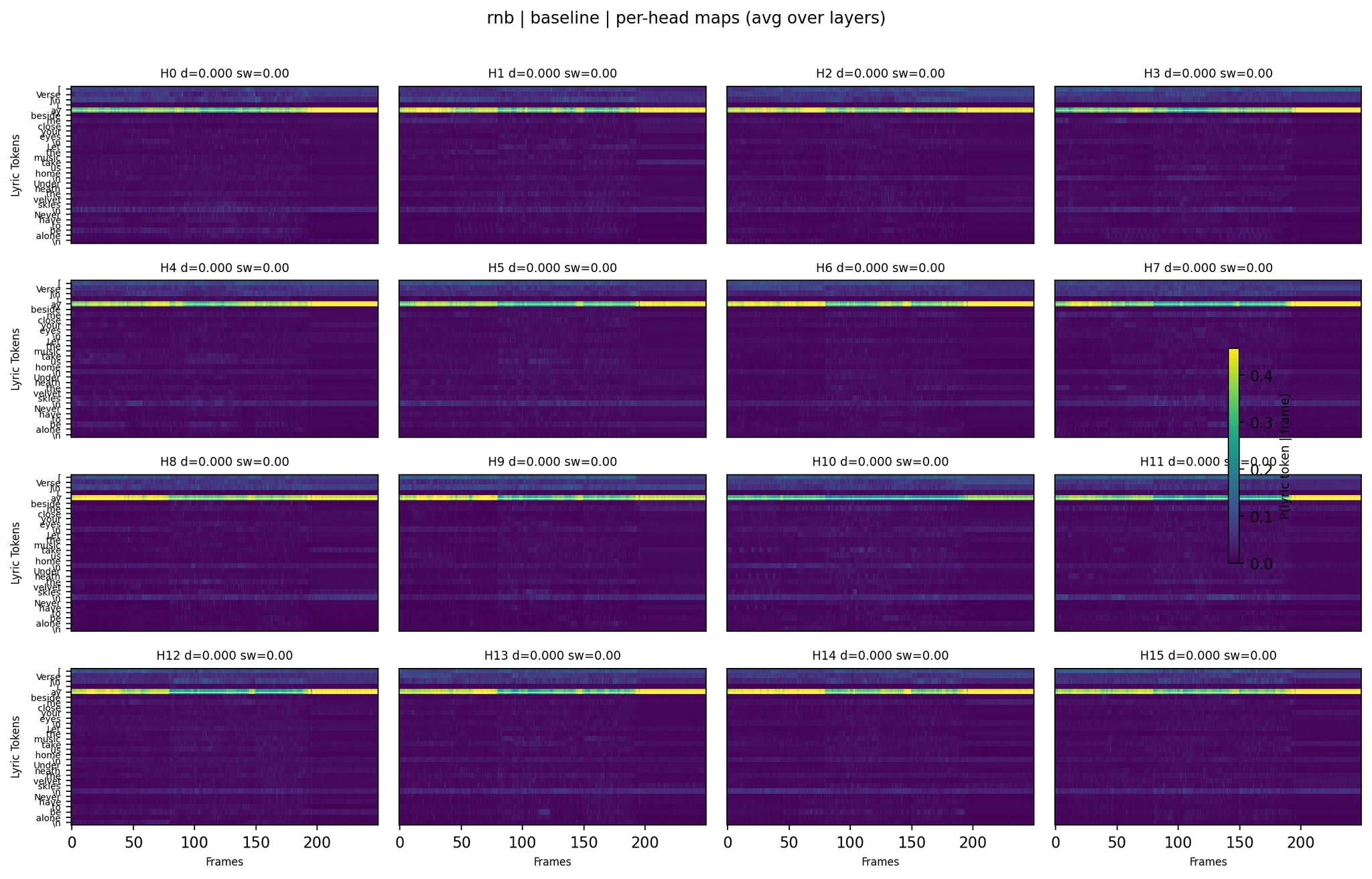
Per-Head Attention - R&B Baseline
R&B LoRA (no lyrics):
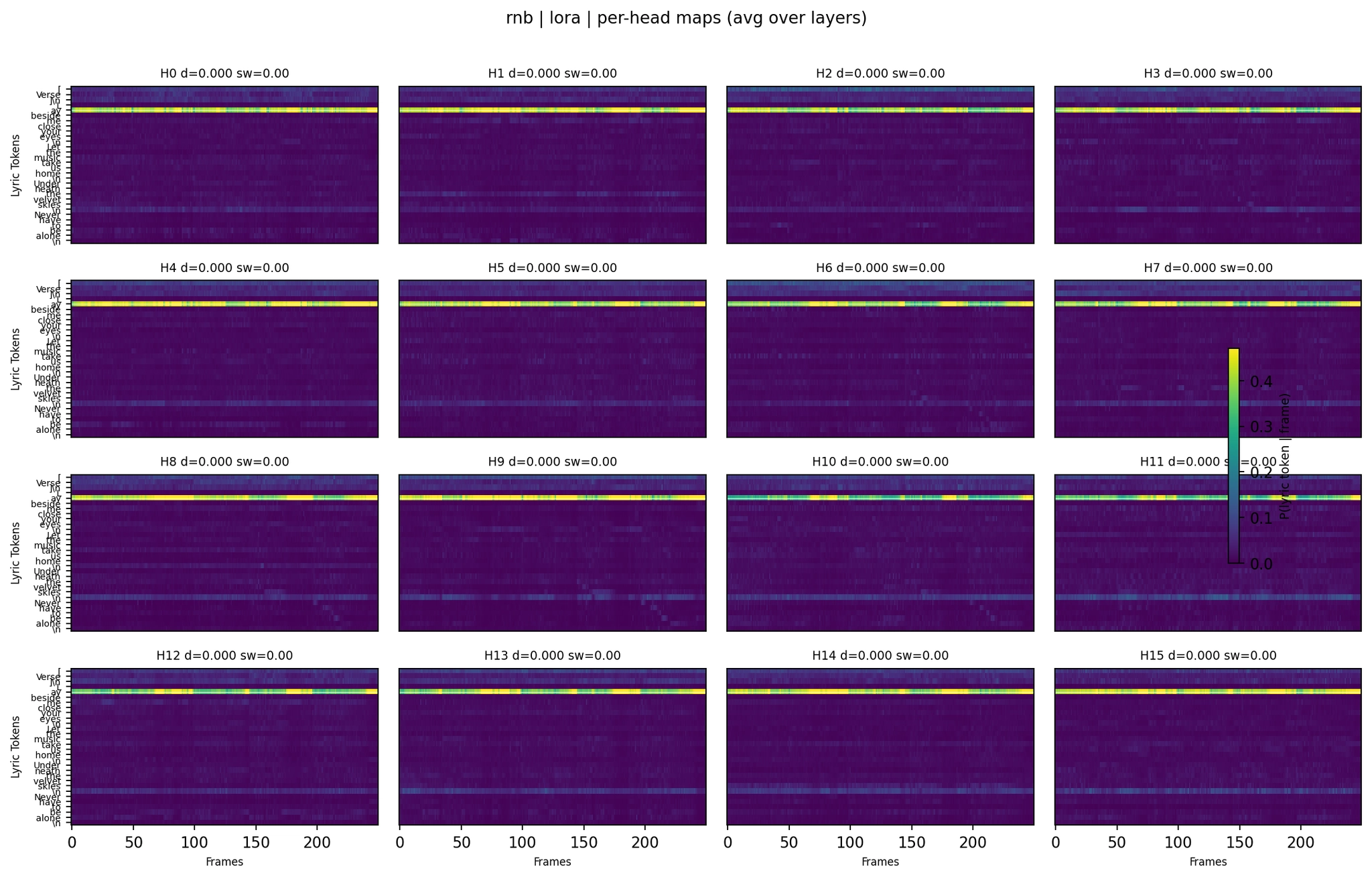
Per-Head Attention - R&B LoRA
R&B LoRA with Lyrics:
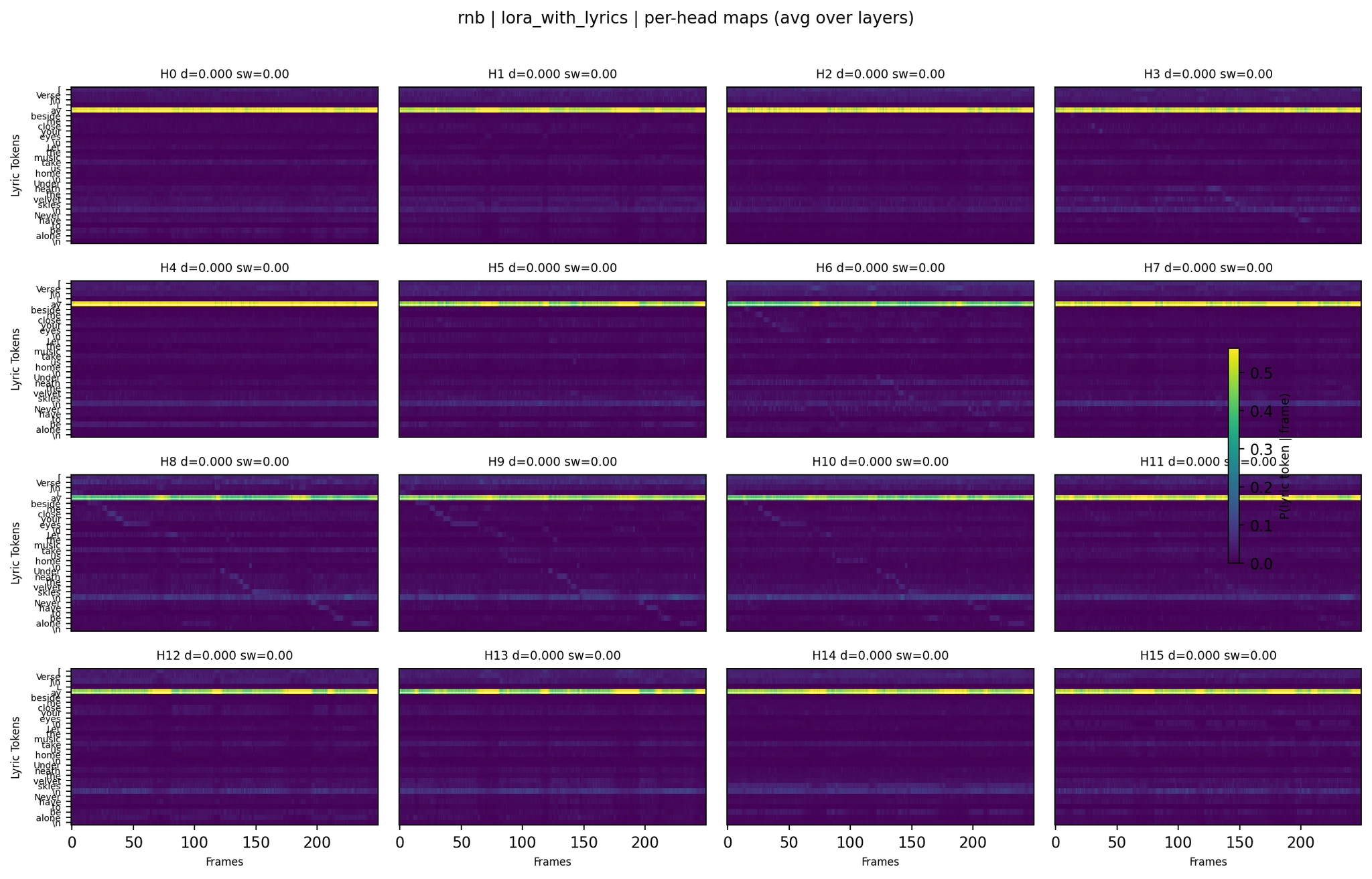
Per-Head Attention - R&B LoRA with Lyrics
The per-layer-head statistics quantify what the figures show qualitatively. For each of the 384 layer-head combinations (24 layers × 16 heads), the deep-analysis pipeline computed a “diagonal score” measuring how well the attention path follows the temporal order of lyrics. Here are the best individual heads for folk:
The lyrics-trained model has the highest single-head diagonal score for folk (0.224, with 0.77 correlation to temporal order). And something interesting: this best head lives at Layer 3 - one of the earliest DiT layers. In the baseline, the best alignment head is at Layer 15, deep in the network, while no-lyrics LoRA also peaks early at Layer 3. This suggests LoRA adaptation can shift strong alignment heads earlier, with lyrics-trained LoRA giving the strongest early-layer score in folk. This could be significant - early-layer alignment means the temporal structure is established before the deeper layers handle higher-level musical decisions.
Across all four genres:
The lyrics-trained model matches or exceeds the baseline’s best diagonal scores in folk and pop, while jazz and R&B show the baseline maintaining higher scores. The pattern is inconsistent - further evidence that alignment is a fragile, genre-dependent property rather than a robust global capability.
The per-head analysis tells a consistent story across all five variants:
dominant_fraction = 1.0 - A single token gets ALL the attention at every time step. Common sink tokens: \\n, [, and common words like “the.”Go back to the cross-attention heatmaps from earlier - now with all five panels visible.

Cross-Attention Maps - Folk (5 variants)
The LoRA with lyrics panel (fourth) shows a different attention distribution compared to LoRA without lyrics. There’s more lyric mass (the lyric portion of the heatmap is brighter relative to the summary), consistent with the deep-analysis metrics showing lyric mass of 0.64 vs 0.48. The LoRA+lyrics+ASR panel (fifth) is the most striking - overwhelmingly concentrated on lyric tokens with sharp, distinct bands. This is what a lyric mass of 0.84 looks like.
Cross-Attention Maps - Jazz (5 variants)
The lyrics-trained model improved jazz WER from 0.42 to 0.21. The heatmap shows why - the fourth panel has more distributed attention across lyric tokens compared to the third panel (LoRA+ASR, which is nearly uniform). The fifth panel (lyrics+ASR) shows extreme lyric focus but in a less structured way.
Cross-Attention Maps - R&B (5 variants)
R&B tells the story of the complementary models. The second panel (LoRA without lyrics, WER 1.00 - “So So So So So”) shows attention that looks reasonable at the aggregate level but completely fails at generation. The fourth panel (LoRA with lyrics, WER 0.38) has a different distribution that actually produces recognizable lyrics. Summary-level heatmaps continue to be unreliable predictors of output quality.
Cross-Attention Maps - Pop (5 variants)
The second panel (LoRA, WER 0.00) and fourth panel (LoRA with lyrics, WER 0.05) look qualitatively similar, and both produce excellent results. The fifth panel (lyrics+ASR, WER 2.10) shows strongly concentrated attention - the model focuses heavily on lyrics but still generates off-target text.
Note: this ablation table comes from a separate 6-case development sweep and is not derived from eval_output_5way/results.csv.
Four experiments, five model variants, 150 generated songs, and hundreds of per-head attention maps later - here’s what this project taught us about LoRA fine-tuning on diffusion transformers.
The most fundamental finding: LoRA without lyrics improved vocal clarity (the model sings more clearly), while LoRA with lyrics improved lyric alignment (the model sings the right words at the right time). These are different skills, and they help in different situations.
Vocal clarity helps when the model is already trying to sing but producing garbled output - pop, rock, synthwave. Lyric alignment helps when the model isn’t singing at all - it provides an activation signal that says “there are words here, sing them” - soul, disco, lullaby.
This separation wasn’t obvious ahead of time. You might expect that training with aligned lyrics would subsume the benefits of training without them. But the lyric alignment training introduces a different optimization pressure on the cross-attention weights, leading to a different (not strictly better) adapter.
Both adapters have identical architecture - rank 8, alpha 16, 5.5M parameters, same target modules. The only difference is the training data’s lyrics field. Yet they produce complementary models that succeed and fail on entirely different genre sets.
This tells us that a rank-8 update to the cross-attention projections is expressive enough to encode qualitatively different behaviors: “make the voice cleaner” versus “align the words to audio timing.” The low-rank bottleneck doesn’t force both training objectives into the same subspace - there’s apparently enough representational capacity at rank 8 for these to be distinct solutions.
The 2×2 ASR experiment provides the cleanest controlled result:
Without lyrics, ASR causes attention collapse to padding tokens. With lyrics, ASR forces attention to real word tokens - useful in principle, still too aggressive at λ=0.02. Entropy regularization on cross-attention requires meaningful conditioning content to work.
The lyrics+ASR model has the best AAS of any variant (0.166) yet worse WER (64.23%) than both simpler LoRA models (~47%). This clearly shows that structured attention patterns don’t automatically produce correct lyrics.
The attention tells the model where to look. Turning that information into correct phonemes requires the value and output projections to encode useful phonetic representations - and those apparently need more training under an aggressive entropy penalty. The model learned where to look before it learned what to do with what it found.
Across all five variants and all per-head analysis, the model treats lyrics more like a global conditioning signal than a word-by-word temporal guide. Most attention heads collapse to sink tokens. Only a sparse subset shows temporal movement. Even the best individual heads achieve 0.77 correlation with temporal lyrics order - strong but far from the clean monotonic alignment in a TTS system.
This suggests that truly solving lyric intelligibility in music diffusion models may require architectural changes - explicit alignment modules, duration predictors, or phoneme-level conditioning - rather than better training data or regularization alone. The cross-attention mechanism in the DiT is powerful but wasn’t designed for precise temporal text-audio alignment.
The hypothetical “oracle” that picks the best model per genre would likely outperform any individual variant. The practical implication: build a routing mechanism that selects the right adapter based on genre or prompt characteristics, or explore weight-space merging techniques (adapter arithmetic at different scales) to capture complementary strengths in a single model.
Numbers and heatmaps only tell half the story. Below are generated audio samples for pop across all five model variants, using the same prompt and lyrics from the evaluation. Put on headphones and try to follow the lyrics as you listen.
Note: these audio clips were generated in a separate run from the main evaluation. Diffusion models are sensitive to CUDA nondeterminism, so even with the same seed, the outputs differ between runs. The WER values below are from the Whisper transcription of these specific audio files, not from the main evaluation tables above.
Ground truth lyrics (Pop): “I can feel the rhythm tonight / Dancing underneath the stars / Every heartbeat burning bright / Nothing in the world is ours”.
These samples illustrate the stochasticity of diffusion generation - the ranking between models can shift across runs. The aggregate statistics over 30 genres in the tables above are more reliable than any single sample. These audio clips are best used to get a qualitative feel for each model’s vocal character rather than as definitive WER benchmarks.
This started as a random experiment on a Friday night - throw some clean vocal data at a music generation model and see what happens. A preprocessing bug turned it into a natural ablation study. A failed entropy penalty taught us more about cross-attention dynamics than a successful experiment would ever do. That’s kind of how life rolls too, in some ways!
- Karthik
