
Research
Phoenix-4: Real-Time Human Rendering with Emotional Intelligence

Written by

Eloi Du Bois
Introducing Phoenix-4, the most advanced real-time human rendering model ever built.
Humans evolved to communicate face to face, using it to build trust and connection. We speak as much through our words as we do through our gestures and expressions. A furrowed brow signals concern before a word is spoken and a slight nod mid-sentence tells the speaker they're being understood. A shift in expression from neutral to warmth can turn a transactional exchange into a moment of genuine connection. We process these signals constantly, unconsciously, and they shape how we feel about every interaction we have. When those signals are missing or out of sync, interaction feels empty and unnatural, and this remains the fundamental problem with conversational AI today.
Achieving this human-like state requires a completely new approach, one that orients around how we actually communicate: through expression, through the ability to convey understanding non-verbally while listening, and through emotional responses that match the context and meaning of a conversation rather than simply reacting to sound. This is the foundation of human computing, teaching machines the art of being human, and it is what Phoenix-4 is built to deliver.
Phoenix-4 is the first real-time model to generate and control emotional states, active listening behavior, and continuous facial motion as a single, unified system. It is a real-time behavior generation engine, built from the ground up, that goes beyond photorealism to transform conversation data into emotionally responsive, context-aware facial expression and head motion with millisecond-level latency. It is a full-duplex model that listens and responds simultaneously, generates every pixel from the full head and shoulders down to individual eye blinks, and gives you explicit control over how emotion is expressed across both speaking and listening states. No other real-time model has achieved this.
In order to achieve this, a new approach had to be taken. Phoenix-4 is trained on thousands of hours of human conversational data, where a built-in behavioral model learns the relationship between all parts of the face and head to control them implicitly. Rather than relying on explicit representations or pre-recorded footage, the model learns how humans actually move, react, and express emotion in real conversation, and reproduces that behavior at runtime. Every decision in the architecture, from how emotion is generated to how listening behavior is controlled, is oriented around one standard: nothing is good enough except human.
In real conversation, we subconsciously read the other person's behavior, picking up on subtle signals like eye contact, head movement, pauses, and changes in expression, and getting these signals right is critical to maintaining shared understanding and engagement in a two-way conversation.
Most real-time ‘avatar’ systems today rely on basic puppetry rather than actual understanding of human behavior, resulting in unnaturalness and lack of flexibility. While we're increasingly seeing models that can nail lip sync and rarely get a word wrong, something still feels very off. Common approaches in today's real-time avatar systems include:
It goes beyond just generating video, whereas asynchronous video generation models like Veo3 or Sora just have to follow a prompt and generate in minutes, truly realistic and immersive human-rendering models have to deeply understand, analyze and react to human behavior faster than real time. Anything less and latency or realism suffers.
Phoenix, our foundational rendering model first introduced in 2023, is the visual bedrock of our conversational experience. While Sparrow handles conversational timing and Raven powers perception, Phoenix is what you actually see: the face, the motion, the presence. This is the model that truly brings human computing to you.
Like its namesake, Phoenix-4 is reborn from its previous incarnations. Over the past few years the model has improved in leaps and bounds. Phoenix-1, our initial groundbreaking model, made it possible to model avatars in 3D with NeRFs and control them using LLM and TTS models streaming at runtime. Phoenix-2 made the switch to faster and more powerful 3D Gaussian Splatting, finally breaking the realtime barrier and enabling Conversational Video Interfaces for the first time ever. Most recently, Phoenix-3 reached new heights of immersion by generating not just the mouth and lips, but the entire face. Now we introduce Phoenix-4, the next evolution of the Phoenix line, establishing behavioral realism, not just visual realism, as the new standard for conversational AI video today.
Phoenix-4 is a real-time facial behavior engine that goes far beyond rendering, translating speech and conversation context into emotionally responsive facial behavior in real time. The model translates speech and conversation context into emotionally responsive facial behavior in real time, generating contextually appropriate emotional reactions.Combined with Raven-1 for perception, Phoenix-4 can interpret emotional context, listen actively, control head pose contextually, and generate emergent micro-expressions. The result is full-face, identity-preserving behavior at 40fps and 1080p, moving Replicas from scripted animation to genuinely responsive presence.
Phoenix-4 introduces a set of state-of-the-art capabilities that enable continuous emotional expression, active listening, and full-face behavioral realism in real time.
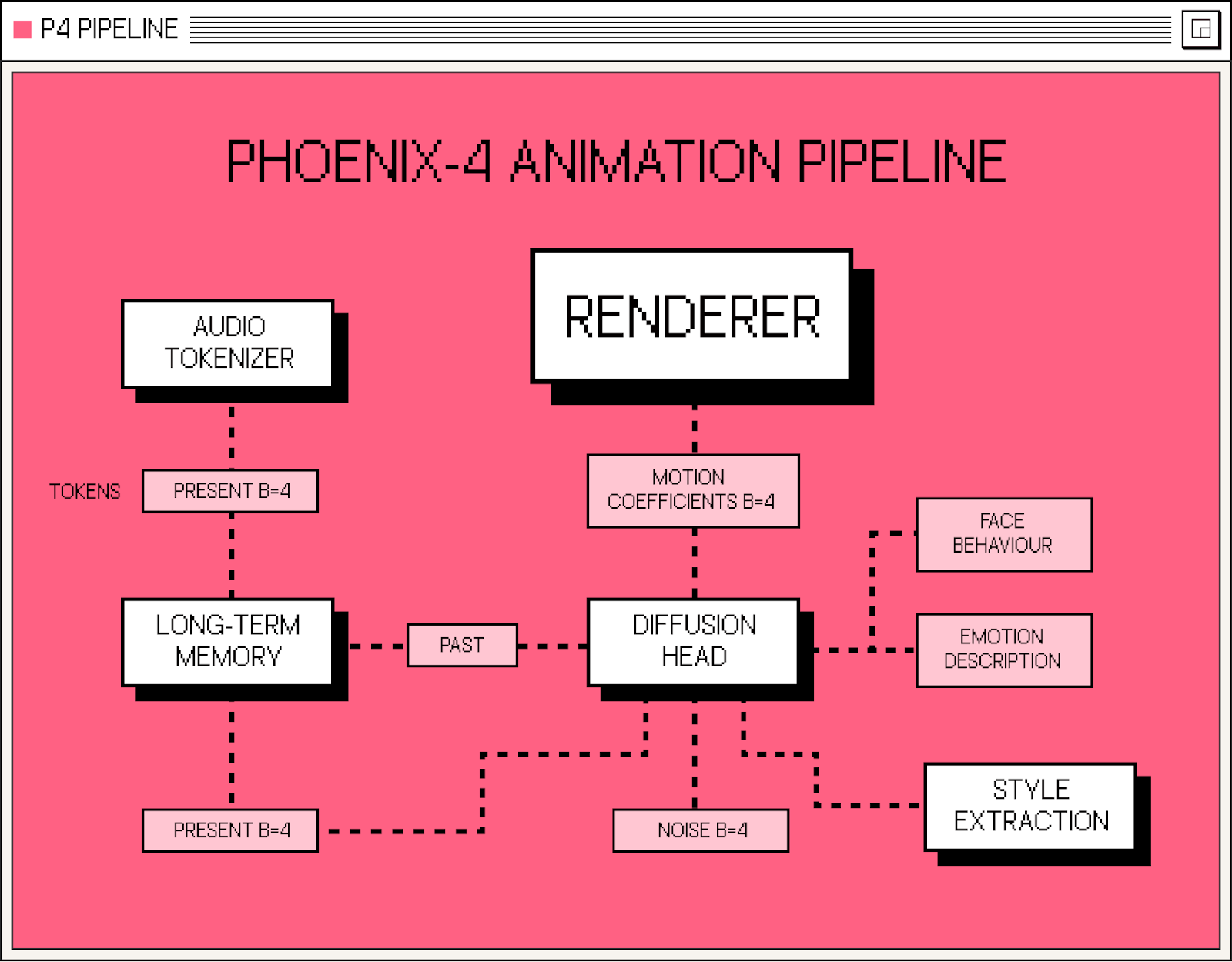
Our overall animation pipeline: an audio feature extractor analyzes audio frames and extracts tokens for the frames we want to generate. A long term memory module analyzes the incoming frame in conjunction with the past frames it saw and produces features that are passed to a diffusion head. The diffusion head takes noisy frames and generates plausible motion coefficients given the past audio features and all other conditions. This results in denoised motion coefficients that drive the image decoder, which ends up rendering the resulting face in image space.
To generate responsive facial behavior in real time, Phoenix-4 first needs a streaming-friendly representation of audio that captures both timing and conversational meaning. Audio tokenization is a widely studied problem, in our architecture, we used a standard features extraction, which we adapted to be streaming friendly (in terms of causality and latency). We then used a type of network which allows us to capture long term semantic dependencies while staying streaming friendly. This gives us strong features to condition the rest of the animation network.
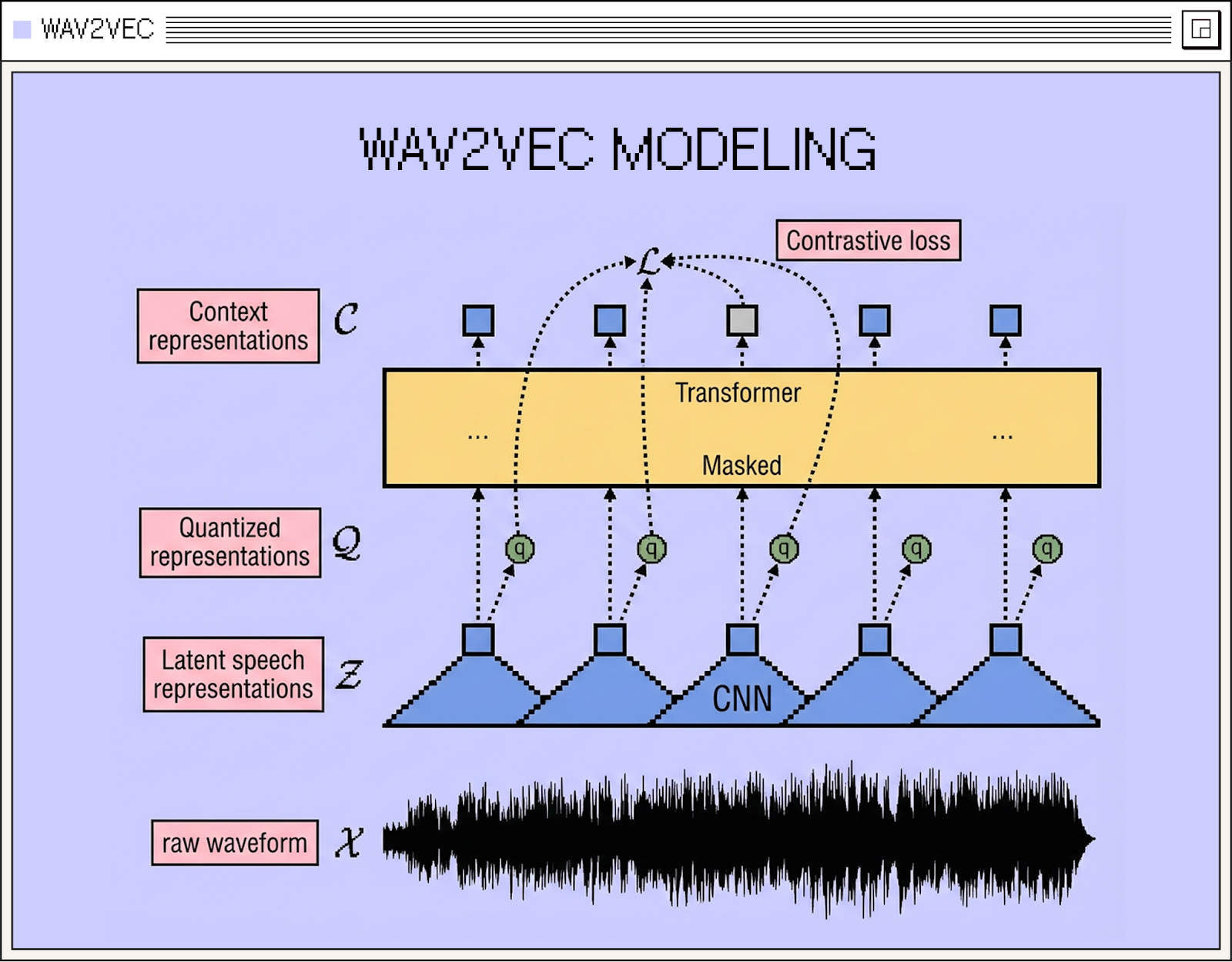
Wav2vec 2.0 (for example, not used in our architecture) learns speech representations from raw audio using a CNN feature encoder, a Transformer context network, a vector-quantization module, and a contrastive loss defined on masked time steps. This diagram shows raw waveform → CNN features → masking → Transformer context → contrastive loss against quantized targets. This objective encourages the network to learn high level features from raw audio, which plays a very important role in the good convergence of audio to animation architectures.
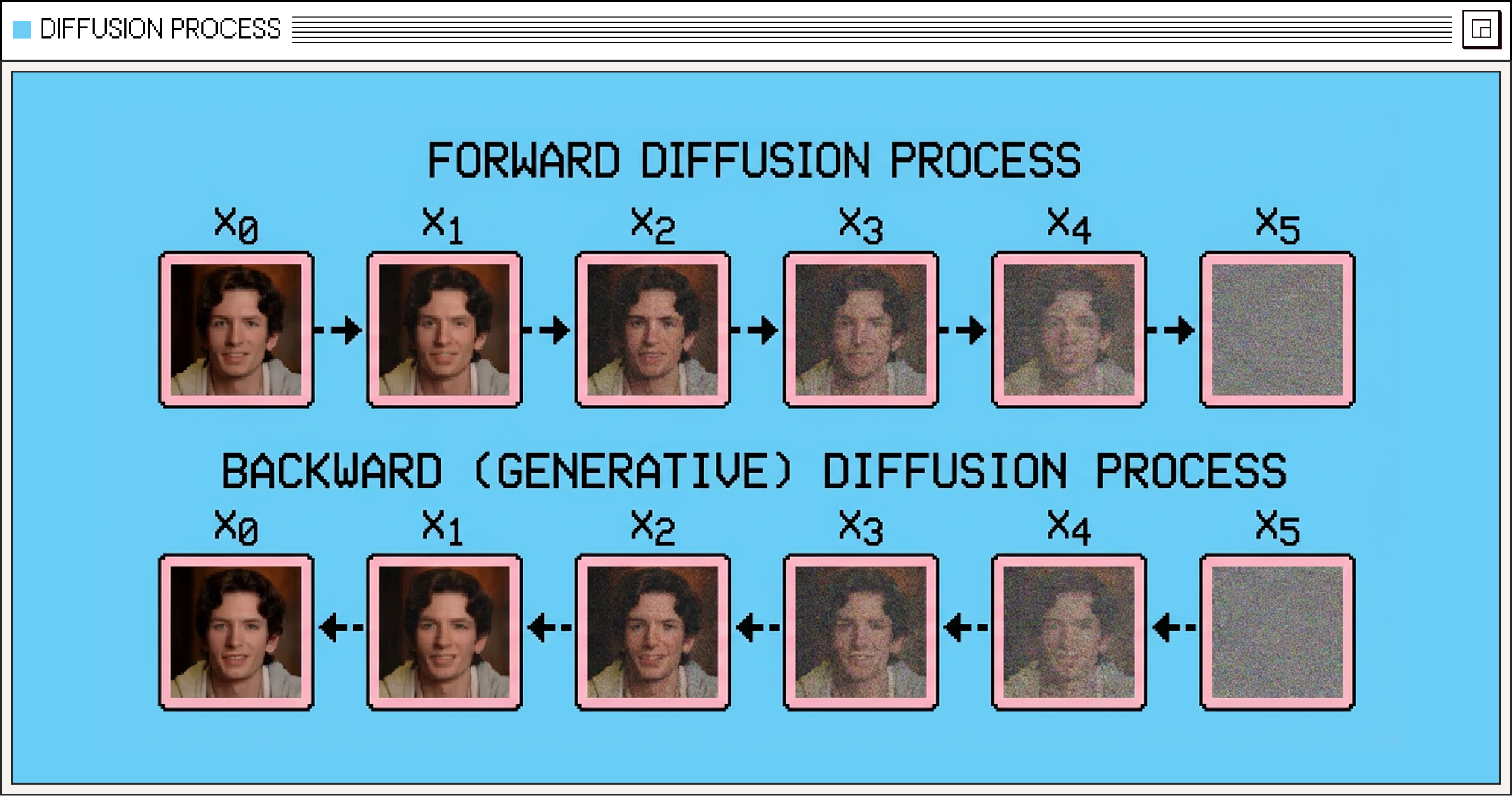
Phoenix-4 uses diffusion-based generation to produce stable, context-aware facial motion that evolves smoothly over time rather than reacting frame by frame. Diffusion models work by learning how to reverse the perturbation of a signal (generally some gaussian noise), where at each timestep, a neural network has learnt to move closer to the target distribution.
A classic approach to guide the noise diffusion with conditional input (emotion, audio, etc…) is to use classifier free guidance. This technique involves randomly dropping out the condition at training time and, at inference time, adding contrast between the conditional and unconditional output, resulting in a way to “boost” the response to one or many conditions. We discuss this approach in depth in this blog post.
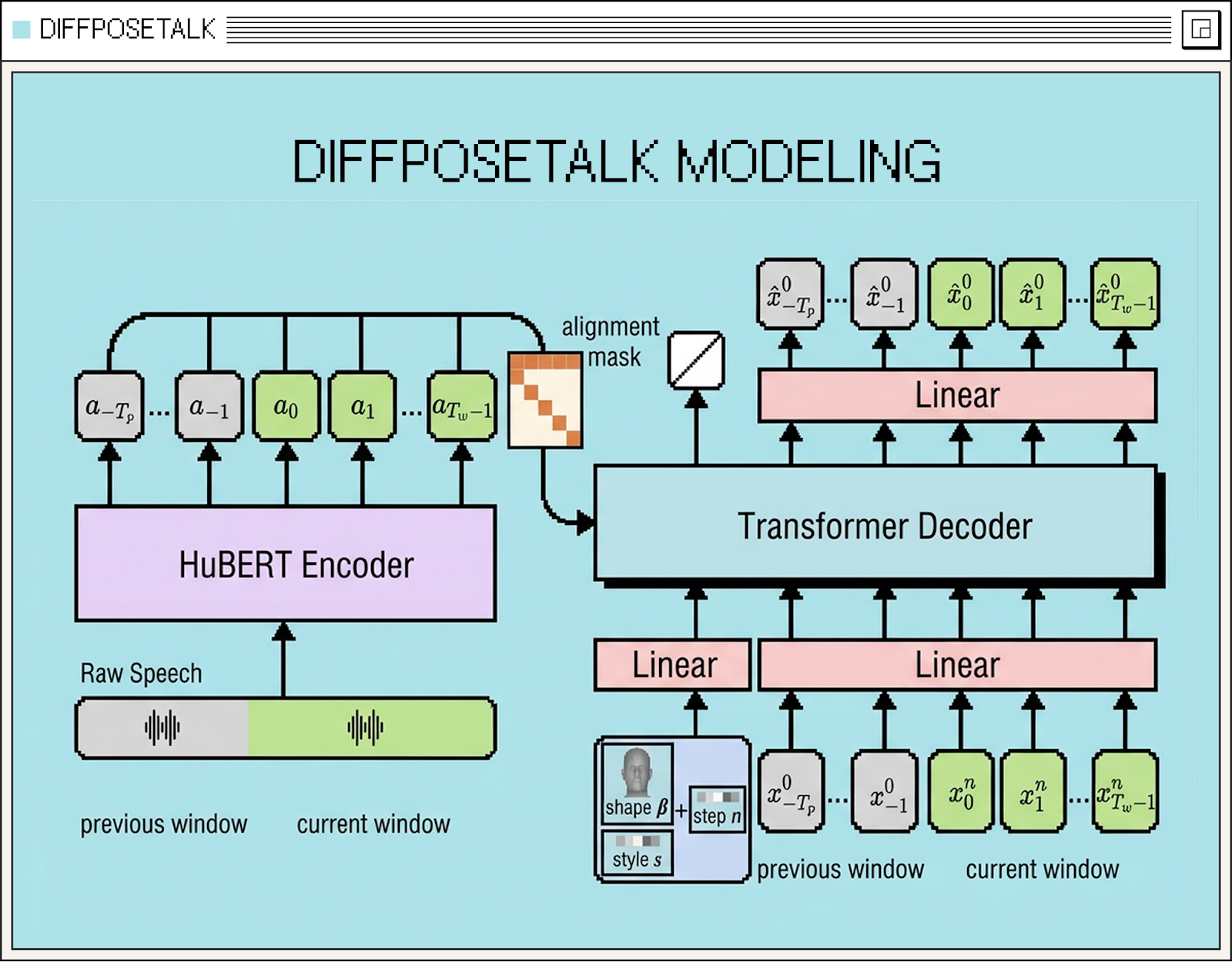
DiffPoseTalk shows how diffusion models can be designed to generate stable facial motion using only past context, a key requirement for real-time facial animation systems like Phoenix-4. In this architecture, a window is passed to a transformer. It contains the past audio features and past predictions AND conditions. A positional encoder indicates what is past vs current window vs conditions. The causality mask, which allows realtime / streaming inference, is given a visibility to the past and conditions at each timestep, whereas the current window timesteps cannot attend to future tokens. The style, shape and diffusion timestep are added as conditions by pre-pending to the time dimension, which helps the network to regress the corresponding denoised window without alteration of the conditional latents. The process goes through many diffusion iterations and we end up with a prediction that is stable through time. This architecture works with an “explicit” latent space, namely FLAME coefficients - which subsequently is driving a mesh.
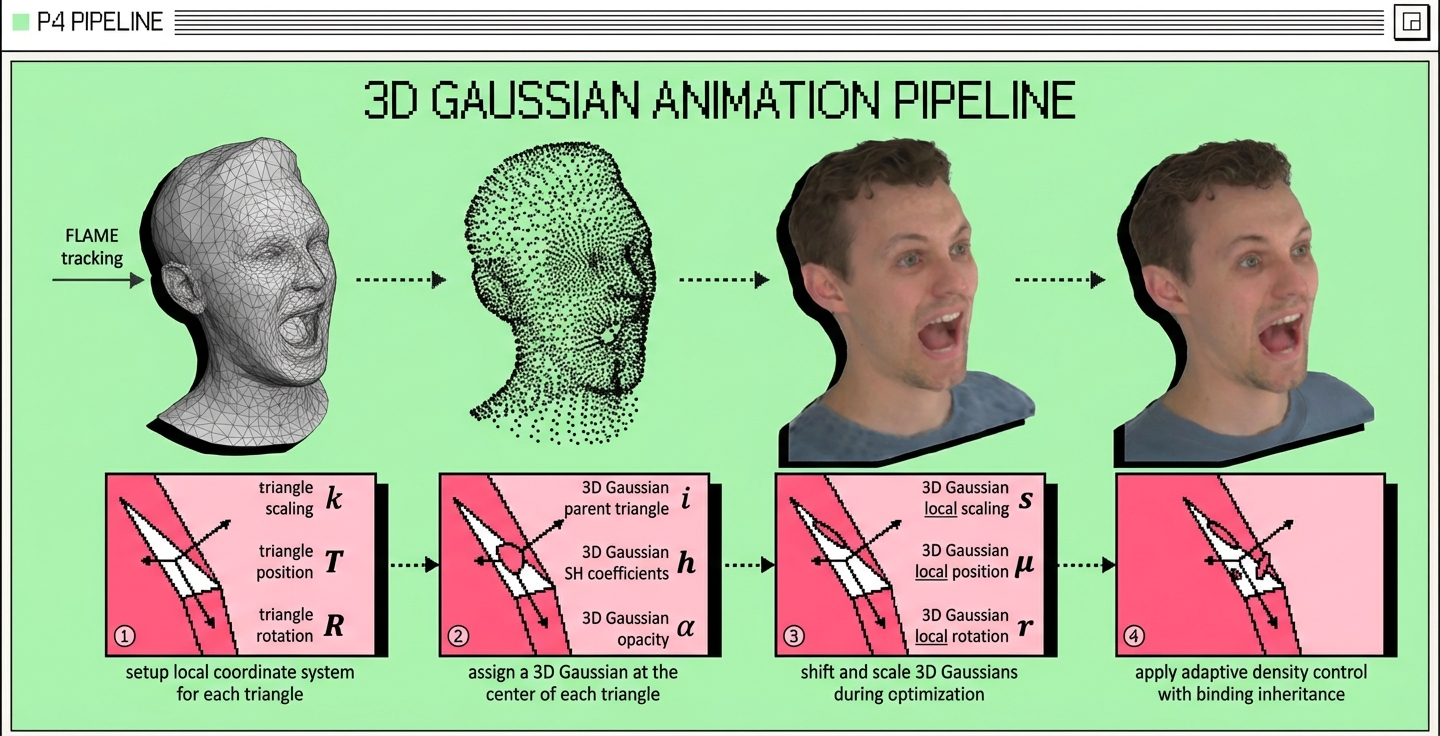
Like Phoenix-3, Phoenix-4 uses 3D Gaussian Splatting (Kerbl et al. 2023) as a rendering engine. Gaussian Splatting is a technique to represent a scene or an object by using hundreds of thousands of parametrized 3-D Gaussians. Each of these Gaussians has a position and orientation in 3D space and is equipped with opacity and a view dependent colour. When rendered together, they are able to represent very complex geometries and lighting effects. While the process of fitting the cloud of gaussians is slow, they are very fast to render. This allows us to produce an image in a fraction of a second, working in realtime. Phoenix-4, unlike other models, uses implicit representation to control the Gaussians in the model directly, bypassing the rigid use of explicit mesh-based control.
Phoenix-4 includes an emotional control system that governs how facial behavior is expressed during interaction. During training, the model learns how different controllable parts of the face such as eyes, brows, mouth, and head pose contribute to emotional expression, allowing it to coordinate these components independently yet coherently based on real human conversational data.
The model supports both automatic emotional responses and explicit control through emotion tags, conditioning inputs, and LLM-driven directives. Phoenix-4's emotional expressiveness is supercharged by Raven-1, our multimodal perception model, which reads the user's tone, facial expression, and intent in real-time. Phoenix-4 uses that understanding to drive its facial rendering, creating a perception-to-expression loop where your Replica listens, understands, and reflects that understanding back visually. While Raven-1 is not required to use emotion control with Phoenix-4, it is recommended to get the most accurate emotion signals.
Building diffusion-based models is hard. Building ones that run in real time is really hard. Maintaining quality while keeping latency low, and preserving performance across long conversations using small inference chunks, requires advanced techniques. Phoenix-4 relies on distillation methods and causal architectures to make streaming inference possible without sacrificing output quality.
The result: the full pipeline runs at 40fps at 1080p.
But rendering is only part of the system. Phoenix-4 is designed to work alongside Sparrow-1 for conversational timing and Raven-1 for perception, forming a complete behavioral stack for human computing.
In real-time conversational video, low latency and live streaming are now table stakes. The real point of differentiation is whether a system can naturally simulate facial behavior continuously, including while listening and during silence, rather than only animating speech. Phoenix-4 is built around this distinction, sustaining coherent, natural behavior across the full conversational loop.
Feature comparison of real-time avatar models
Every conversation has a moment where we decide whether the person on the other side is actually there with us. It happens unconsciously, and it determines everything that follows. Presence, the feeling that someone is genuinely paying attention, understanding what you’re saying, and responding to what you actually mean, is what makes the difference between a conversation that builds trust and one that feels like talking to a screen. And it’s not about a single expression or gesture, it’s about the feeling those behaviors create together.
This is what has been missing from conversational AI, and it is what Phoenix-4 delivers for the first time. Until now, no real-time model has been able to produce the behavioral signals required for a person to feel genuinely understood by an AI system. Phoenix-4 changes that by generating emotionally grounded, contextually aware presence with the accuracy, timing, and emotional nuance that humans subconsciously expect from a real conversational partner.
The impact is measurable because presence drives outcomes. In healthcare and therapy, a patient who feels understood by their provider is more likely to disclose symptoms honestly, follow treatment plans, and return for follow-up sessions. In education and coaching, a learner who feels that their tutor is actually paying attention stays engaged longer, asks harder questions, and retains more. In sales and customer support, an interaction that feels human rather than scripted drives higher conversion, longer engagement, and stronger brand loyalty. These are the direct result of delivering the behavioral signals that humans rely on to determine whether the person they're talking to actually cares, and Phoenix-4 is the first system capable of producing those signals in real-time.
For any interaction where empathy matters, where presence matters, where the difference between someone engaging with AI and someone actually feeling like there's someone on the other side determines the outcome, Phoenix-4 is what makes that possible.
Together with Sparrow-1 for conversational timing and Raven-1 for perception, Phoenix-4 completes a full behavioral stack for human computing, enabling end-to-end conversational systems that communicate through behavior as well as language. Our goal was to give AI the ability to truly express itself in real time, and Phoenix-4 is the first model that delivers on that promise, not by generating facial movements from audio waves, but by understanding conversation dynamics and producing emotionally rich, controllable responses that transition naturally between states.
Phoenix-4 establishes behavioral realism, not just visual realism, as the new standard for conversational AI video. It defines a new baseline for human computing and the foundation for every human-centered interaction model that follows.
Phoenix-4 is available today through the Tavus platform, APIs, PALs, and our updated Stock Replica library with new replicas trained on the model. Users can also create fully custom Phoenix-4 Replicas tailored to their own likeness or use case now as well.
Try the demo at phoenix.tavuslabs.org and learn more in our docs.
(Qian et al. 2024) GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians. Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain and Matthias Nießner. CVPR2024
(Kerbl et al. 2023) 3D Gaussian Splatting for Real-Time Radiance Field Rendering. Bernhard Kerbl Georgios Kopanas Thomas Leimkühle George Drettakis. SIGGRAPH 2023
