
Research
Raven-1: Bringing Emotional Intelligence to Artificial Intelligence
.png)
Written by

Mert Gerdan
Introducing Raven-1. A multimodal perception system that captures not just what users say, but how they say it, how they look when they say it, and what that combination actually means. It interprets tone, expression, hesitation, and context in real time, enabling AI that can truly understand intent rather than simply respond to words.
Before Raven-1, we built Raven-0 to give AI eyes which could interpret visual context, like a person leaning forward, enthusiastic hands gesturing, or background context. Raven-1 fuses audio and visual into a unified understanding, where tone, expression, and timing inform each other in real time.
Today, most conversational AI understands words, not people. Despite major advances in LLMs and TTS systems, conversational AI still operates on a partial view of human communication. Traditional pipelines rely on transcripts, reducing speech to words while discarding tone, pacing, hesitation, and expression.
This reduction removes essential context from human communication and alters how true meaning is inferred. Hesitation may be read as confidence or uncertainty may appear neutral. Visual cues such as delayed responses, avoidant gaze, or nervous movements are not observed, and as a result, intent is misinterpreted and responses become misaligned.
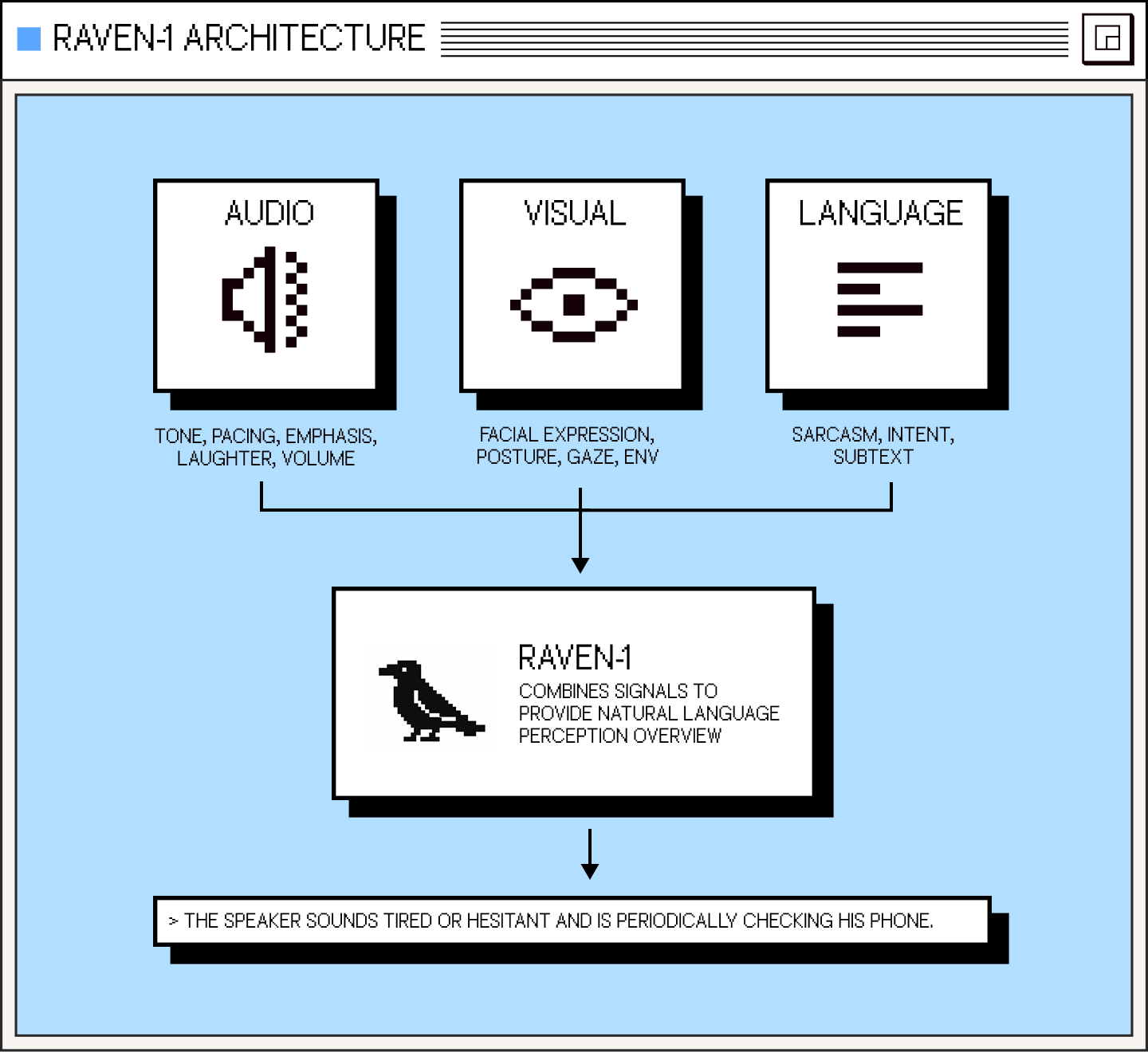
Raven-1 solves this gap by perceiving the full modality space: audio, visual, and temporal dynamics, all processed together and aligned in real time.
Humans evolved to communicate face to face. We convey intent through tone, expression, hesitation, environment, and like a dance, conversations are fluid, layered, and deeply contextual. For example, a single moment of interaction can carry frustration and hope all at once. Meaning lives in what those signals tell us, and they evolve millisecond by millisecond.
But conversational AI today doesn't perceive human communication the way we do- it reduces rich interaction to simple, lossy text. When you strip conversation down to text alone, the meaning disappears entirely. Without that layer, machines can interpret language- but not intent.
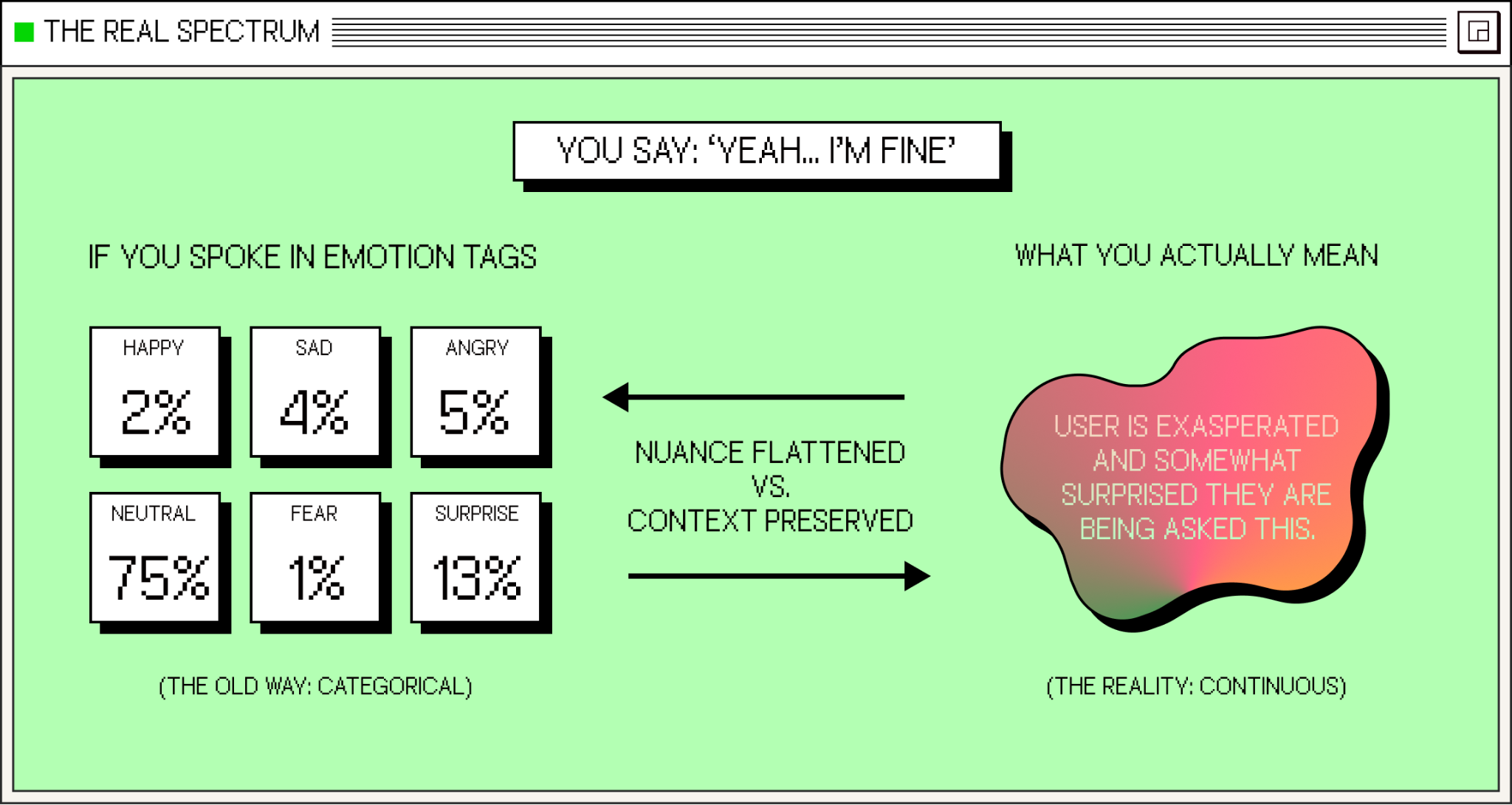
So, when someone says "Yeah, I'm fine," what does that actually mean? Is it genuine? Dismissive? Masking distress? Without the full signal (prosody, facial expression, body language), AI has to guess. And those guesses break down exactly when they matter most: during the ambiguous, emotionally loaded moments that define meaningful conversation.
Modern conversational AI systems depend heavily on transcription as an intermediate representation for understanding human speech. While this approach simplifies downstream processing, it also introduces a fundamental limitation- converting speech into text removes critical information required to paint the full picture, and accurately infer intent, emotion, and context.
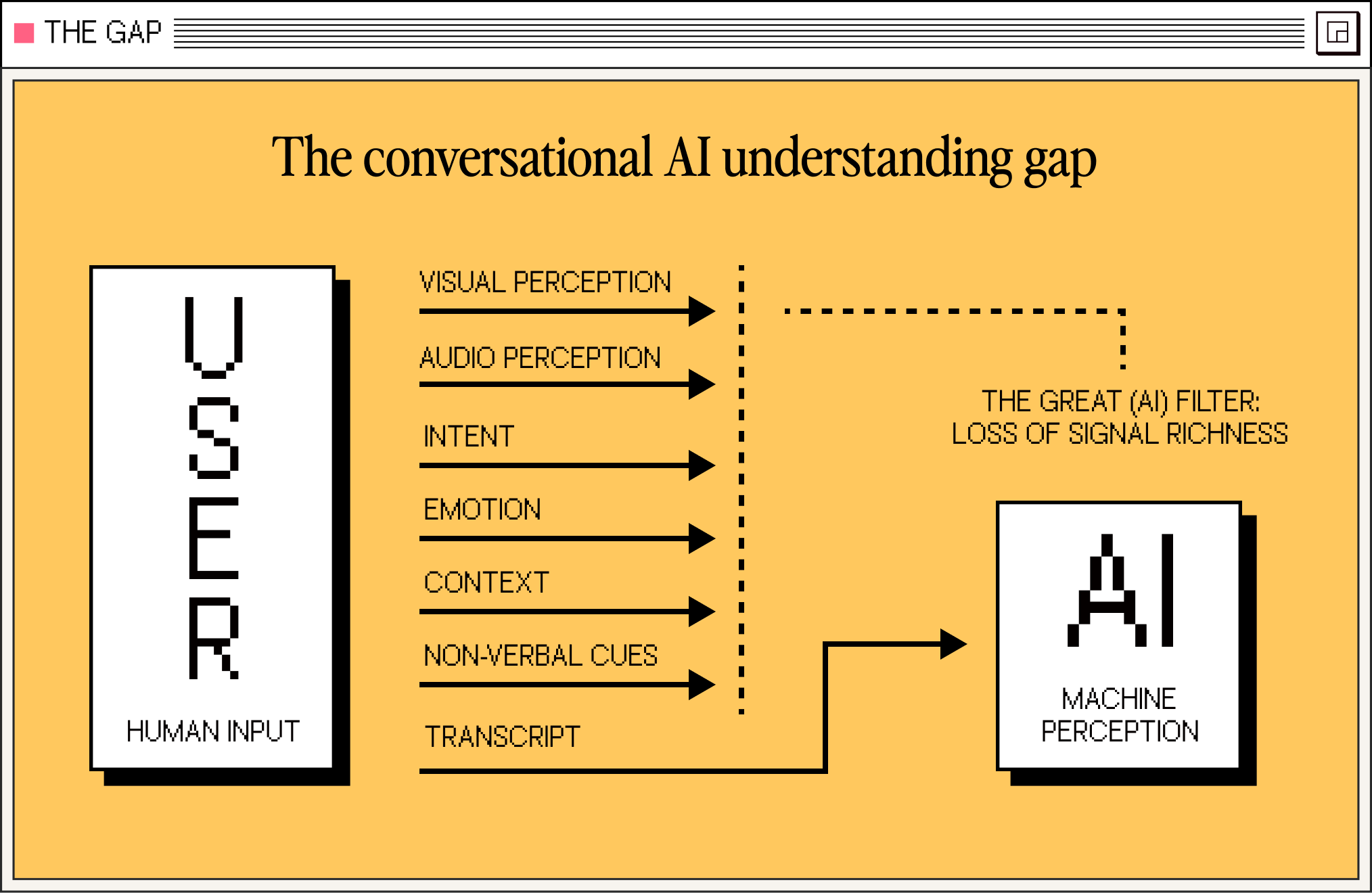
The same challenge applies across modalities. When spoken interaction is understood only by a transcript, critical signals are lost:
Audio signals lost in transcription
Sarcasm. Hesitation. Emphasis. The difference between a whisper and a shout. A pause that signals thoughtful deliberation versus confused silence. All flattened into uniform text.
Visual cues invisible to language models
Someone might be visibly confused, smiling politely, distracted by their environment, or multitasking during a response. Without awareness of these signals, AI misses the real intent.
Temporal dynamics collapsed
A minute-long response might begin with frustration and end with acceptance. Traditional systems can't distinguish these narrative arcs. They process the entire segment as a single emotional state, smoothing away the shifts that carry meaning.
Non-verbal vocalizations ignored
Sighs, throat-clearing, hesitation sounds ("uh", "um"), trailing-off. These aren't transcribed, yet they communicate cognitive load, uncertainty, and turn-holding intent.
It's this signal loss that causes conversations with AI to feel hollow or one sided. Not because the AI can't generate good responses, but because it operates on 30% of the actual context or data needed to execute the dance of a conversation. You have to adapt your communication style to match the AI's limitations, not the other way around.
Most emotion-aware AI systems today attempt to understand users by classifying emotion. They do this by isolating individual signals, typically analyzing a single modality and then mapping those signals into fixed emotional categories. These approaches are often based on outdated or rigid frameworks originally designed for offline analysis such as facial action coding systems (FACS), rather than a real-time interactive conversation.
This approach introduces fundamental limitations as ultimately, human emotions cannot be distilled to discrete labels like "happy," "sad," or "angry". When systems rely on narrow inputs and rigid classifications, they fail to capture how emotion and context is actually being communicated in a conversation.
Even on the audio perception side, each step in the traditional pipeline irreversibly destroys the signal required for understanding. First, you convert rich audio into flat text, losing prosody and rhythm. Then you force that already-degraded signal into fixed emotion categories, losing nuance. By the time you’re done, the original human signal is unrecognizable and the damage is permanent.

Real emotion is fluid, layered and contextual, for example: people can come off frustrated and hopeful in the same breath, or can express skepticism while remaining curious. But categorical systems force discrete choices where humans perceive continuums. And when understanding is broken, everything downstream (response generation, timing, empathy) becomes impossible.
As a result, conversational AI may generate a grammatically perfect response, but it'll feel completely tone-deaf or misaligned. The solution is not more refined categories, but a new system that models emotional state the way humans do, as a continuous, multimodal, temporally aware representation of intent.
Raven-1 was engineered as a native multimodal perception system designed for real-time conversational interaction. Building on Raven-0's visual understanding capabilities, Raven-1 extends that capability across the full modality space by aligning audio and video streams into a unified perceptual representation. It synchronizes audio and visual signals into a temporal frame thus allowing speech, expression, and timing to be interpreted jointly.
By fusing these inputs into a unified and rich representation of the user’s state, intent, and context, Raven-1 is the perceptual bridge required for AI to move beyond mere response and into true understanding. The release of Raven-1 advances our broader vision of building the human computing interface, enabling systems to perceive human signals in real-time and participate meaningfully in the natural dance of a conversation.
What makes Raven-1 unique is its ability to express a holistic description of human state and visual context in real time, in a form that LLMs can reason over directly.
Raven-1's outputs are natural language descriptions, produced by aligning a conversational embedding model to an LLM. Not categorical labels or numeric scores. For each segment of speech, the system produces interpretable statements:
"The speaker sounds surprised and slightly skeptical with a hint of amusement or irony."
"The speaker is expressing fake enthusiasm with a hint of sarcasm and annoyance."
"The user appears disengaged, looking away from the screen while giving short responses."
This approach preserves nuance that categorical systems discard. It allows for compound emotional states, hedged interpretations, and temporal qualifiers. And critically, it produces outputs that downstream language models can directly consume. No translation layer required.
Raven-1 operates at a sentence-level temporal resolution. A long utterance produces multiple descriptions that reflect how the speaker’s state evolves throughout a single turn. This allows conversational systems to detect shifts such as
Categorical systems collapse these arcs into single labels. Raven-1 preserves them, enabling downstream systems to respond based on how the interaction is unfolding rather than on a static classification.
Raven-1 was designed from the ground up for real-time operation without delivering any additional latency. At total pipeline latency under 600ms, every millisecond matters. Conversational AI needs the flexibility to respond at the right time. Sometimes instantly, sometimes after deliberate pause.
The system excels on short, ambiguous, emotionally loaded inputs. A single word like "sure" or "fine" carries radically different meanings depending on delivery- Raven-1 captures that "how" and makes it available to response generation.
Speed alone doesn't solve perception though. What matters is that understanding is never more than 300ms stale. Raven-1 continuously updates its representation of the user's state, ensuring that responses reflect the current emotional and attentional context. Not a snapshot from just a few seconds ago.
This rolling perception enables the system to track shifts in real time: frustration intensifying, attention drifting, confusion building, the goal is for the AI humans response to adapt accordingly.
Raven-1 supports custom tool calling via OpenAI-compatible schema. Developers can define specific events (a user laughing, an emotional threshold crossed, attention shifting away) and receive callbacks when detected.
This enables domain-specific automation:
Lossy perception makes empathy impossible. And without empathy, conversational AI will never truly be human
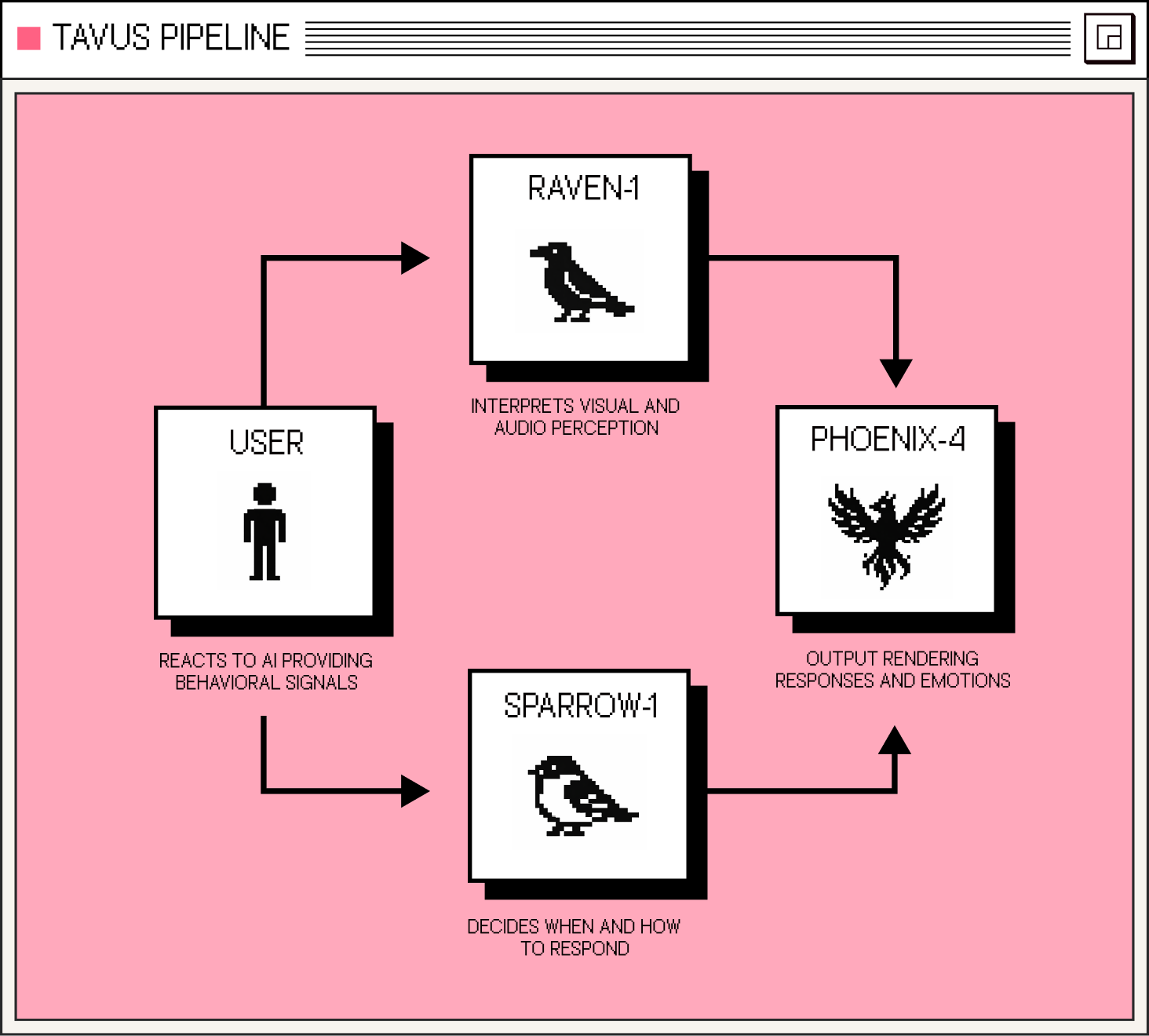
Interpreting signals is only half the equation. The real impact comes from using the signals in real time to shape how the AI responds.
In the Tavus stack, Raven-1 works alongside Sparrow-1 (our conversational flow model) and Phoenix-4 (our emotional rendering system). It's a closed loop to craft a more human experience: perception informing response, response reshaping the moment.
In testing, Raven-1's perception layer dramatically improves AI conversation quality, depth and naturalness across the board:
The use cases where multimodal perception matters most share a common thread: the conversation itself is the product, not just a means to an end. When the goal is human health or professional development, "good enough" understanding is a failure state.
Raven-1 unlocks empathetic AI that wasn't possible before: from healthcare that recognizes patient discomfort in real-time, to companions that understand subtext, sarcasm, and shifting intent, to support agents that adapt as frustration rises.
This level of understanding of human emotion and intent opens up entirely new possibilities:
We built Raven-1 as part of a broader mission: teaching machines to participate in human conversation. When machines really understand us, it unlocks a future where we don’t have to think about how to interact with them. We can treat them just like our friends or coworkers. It becomes second-nature.
The uncanny valley isn't about how the AI sounds or looks- It's about whether it actually understands you. Responses that miss your sarcasm, ignore your frustration, or plow through your hesitation remind you that you're speaking to a system rather than a partner. Raven-1 unlocks the machines ability to “hear” and “see” just like us, and with it’s understanding, enables a new standard of interactions that feel truly attentive, empathetic, and natural
Raven-1 is now available across all Tavus conversations, introducing a new perception layer for building more human conversational experiences. The model works automatically out of the box, and Raven's perception layer, exposed through Tavus APIs, makes it possible to add tool calls and programmatic logic that leverage real-time understanding to drive better outcomes.
Try the demo at raven.tavuslabs.org and learn more in our docs.
