
Product
Introducing Image-to-Replica

Written by

Jesse Rowe
Tavus · Product Launch · May 2026
Imagine a historical figure, an AI character designed from a single prompt, or even a brand mascot that has lived in a logo for thirty years. With Image-to-Replica, every one of these can now hold a real conversation.
A face is the first impression of an AI human. Long before memory, personality, perception, or conversation come into play, the face has already done the foundational work of recognition, setting the tone, establishing trust, and pulling a person into the interaction. It is the first signal of who, or what, they are about to talk to, and the first reason they decide to keep talking.
Until today, every Tavus AI human began at the same place: a video recording session of roughly thirty seconds of speaking and thirty seconds of listening, captured under decent lighting by someone able to sit on camera. That session produces excellent replicas of real people, and for the customers it was designed for, it has worked beautifully. But it bounded the universe of possible AI humans to the people who could sit for them, and left out entire categories of faces that customers wanted to bring to life: public figures whose calendars do not bend around studio time, historical figures and loved ones who are no longer with us, brand mascots and illustrated characters that have lived inside logos and storybooks for decades, AI-generated personas designed to spec for a role that has no body yet.
Image-to-Replica expands that horizon. A single image is now enough to produce a fully usable Phoenix-4 AI human, and the set of faces that can become one is dramatically wider than the set of people who can sit on camera.
The Tavus platform that Image-to-Replica runs on already powers AI humans for more than 100,000 developers and many of the world's leading enterprises, including Amazon, Deloitte, EY, Mayo Clinic, CVS, Salesforce, Aetna, and Wix. It is the platform behind real-time AI employees, healthcare intake agents, training and coaching experiences, and customer engagement that runs across millions of conversations every month. Image-to-Replica brings that platform within reach of any face that can exist as a single image.
The expansion is the point because an image takes seconds to produce, is easy to iterate on, and gives the builder direct control over lighting, framing, and creative direction in a way that a one-take recording cannot always provide.
Sales prospects can spin up an AI human from a headshot before a recording session is on the calendar. The path from interested-in-Tavus to talking-to-your-own-AI-human collapses from days to minutes. For developers evaluating CVI, the first AI human can be theirs, or anyone's, without leaving the developer portal.
Public figures whose schedules do not permit studio time. Memorial use cases for people who are no longer here. Human-like brand mascots that have lived in a logo for decades. Each one was previously unreachable and now each one is reachable today from a single image.
A human-like mascot can hold a real conversation. An illustrated character can become a tutor that responds to questions in real time. An AI-generated persona, designed to spec for a specific role, can be deployed as a CVI persona without ever existing in physical form. The unboundedness shows up most visibly here, in AI humans built from faces that were never filmable to begin with.
Developers building a healthcare flow, a coaching app, or a roleplay simulator no longer need to record themselves, or recruit talent, to test a persona. A stand-in can be created in seconds, the experience validated end-to-end, and a full video training committed to only when the use case earns it. Build first, polish later.
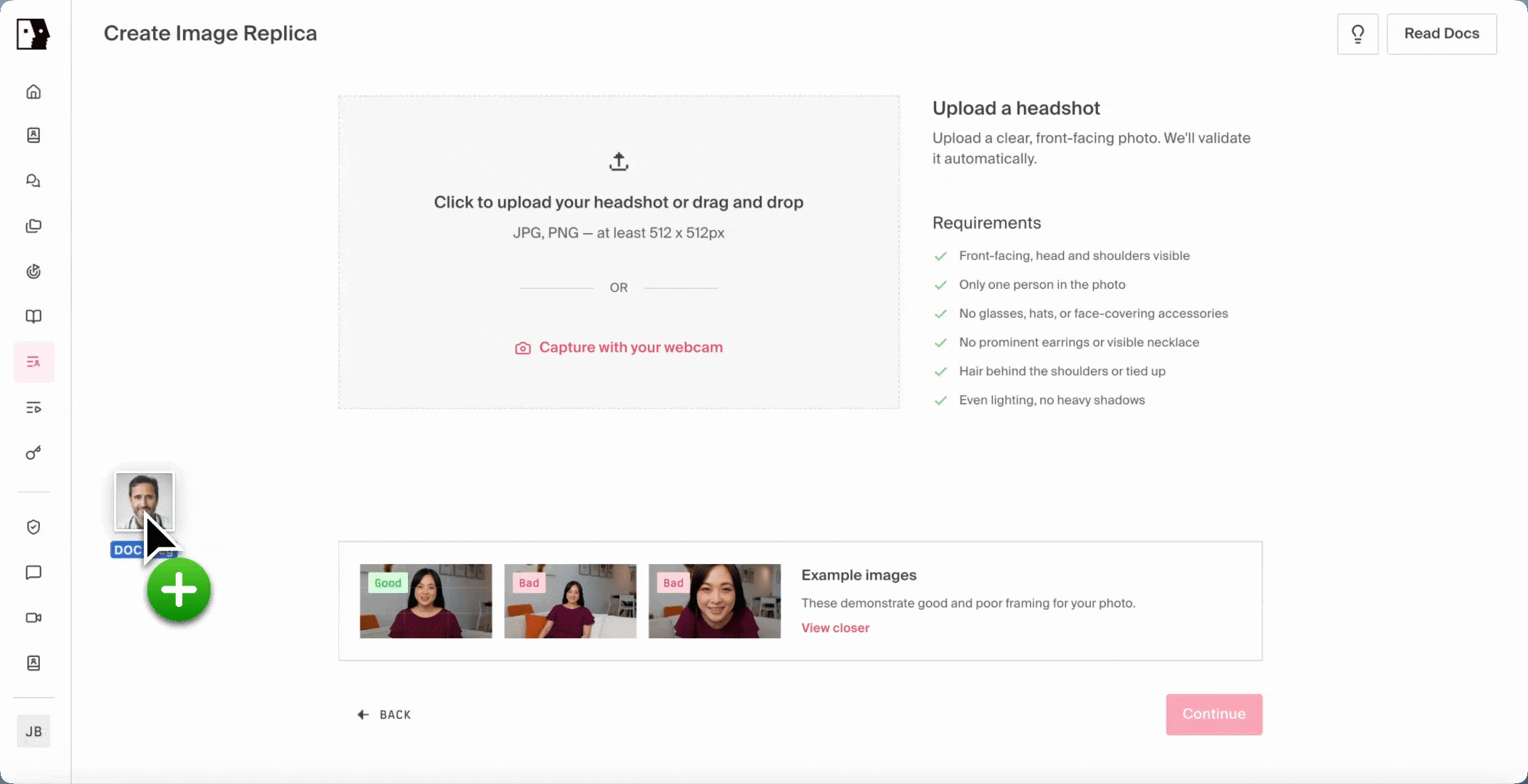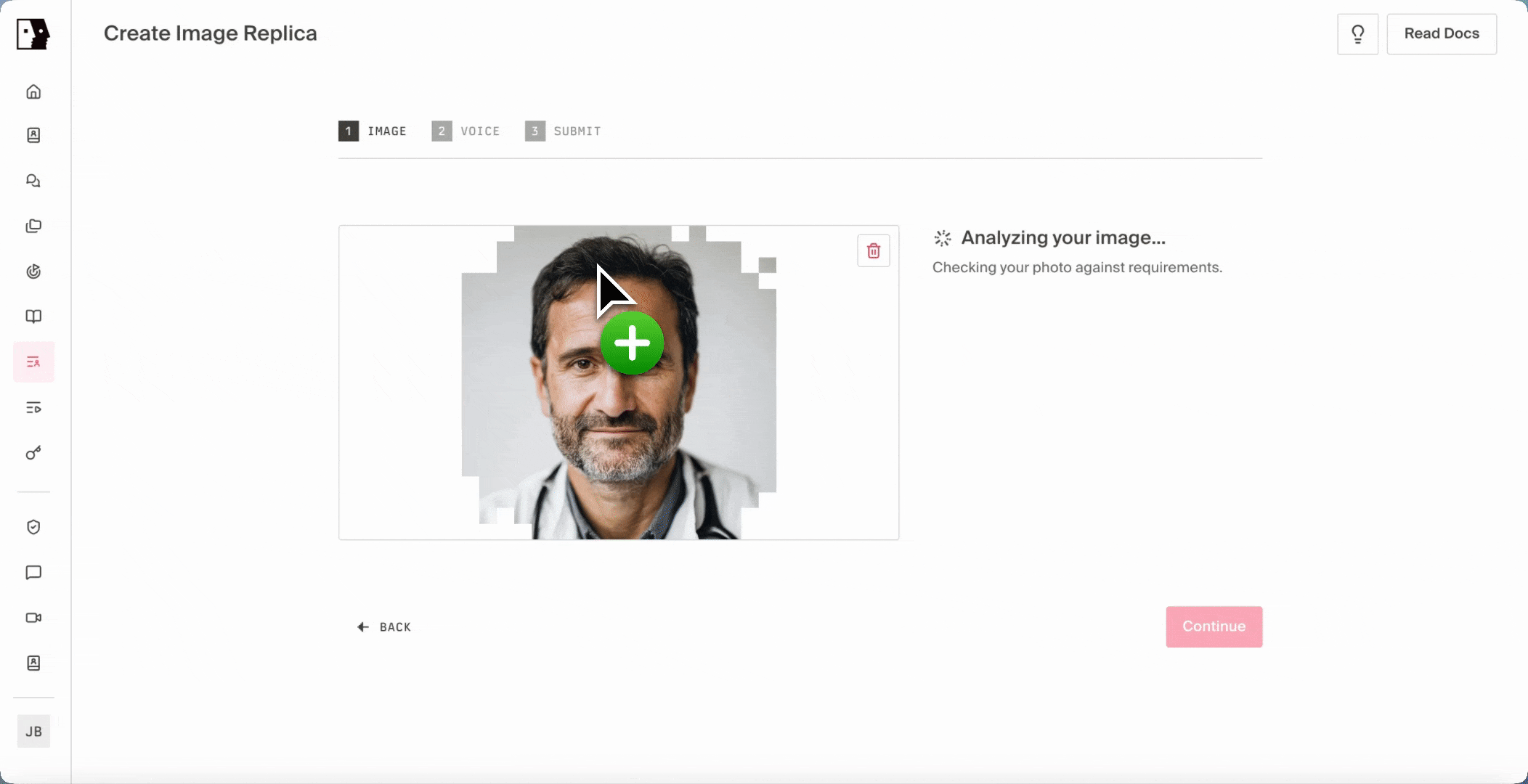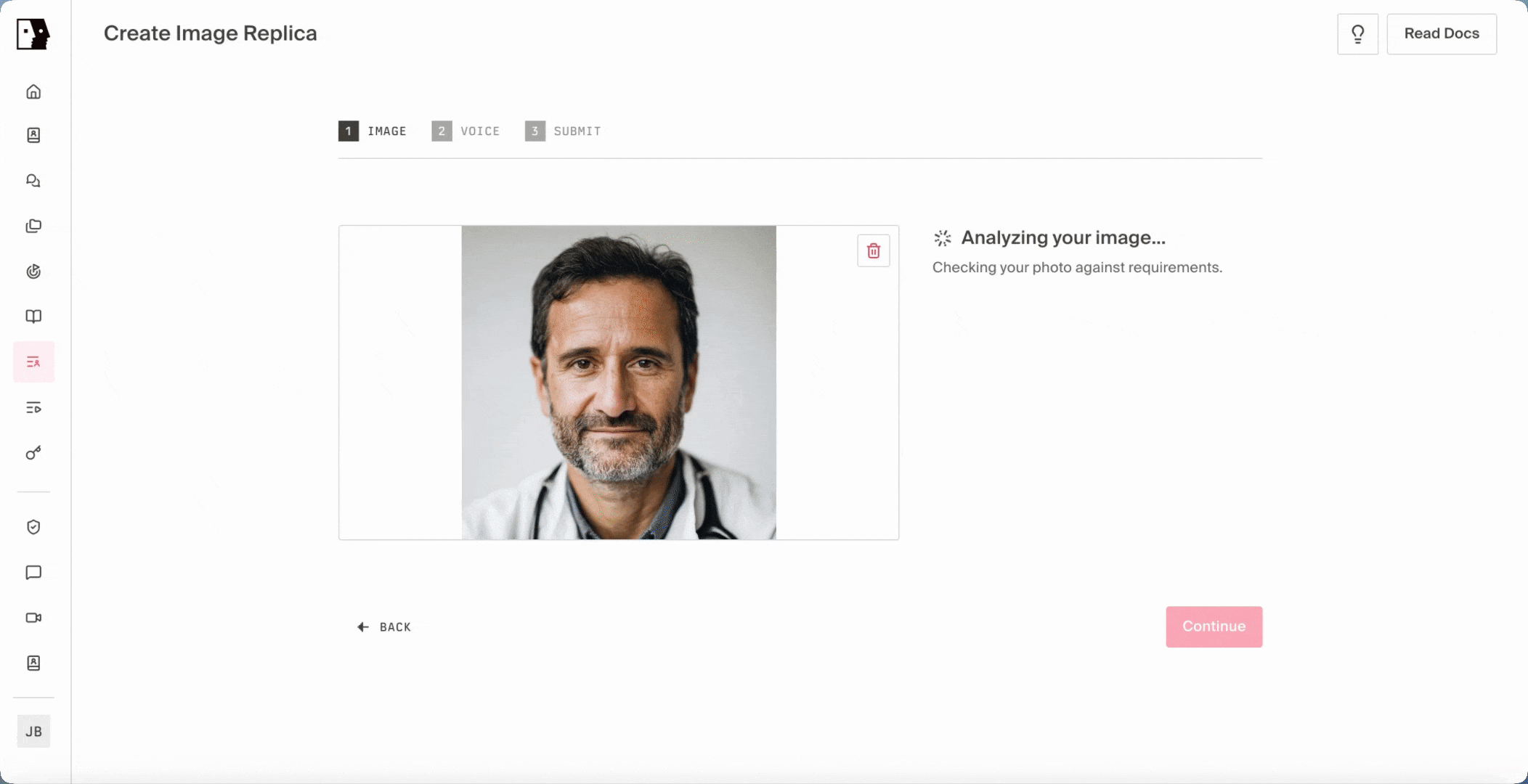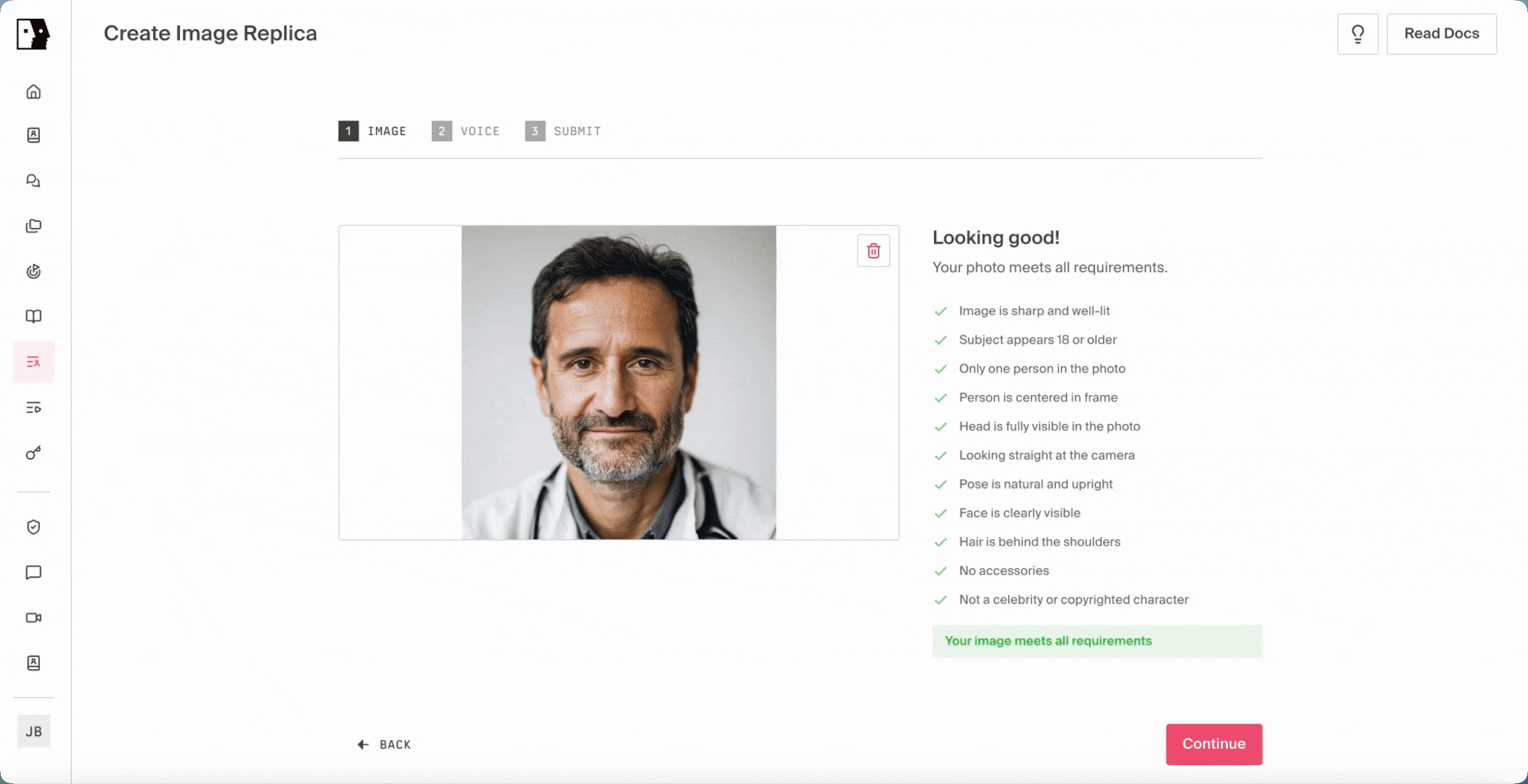
Image-to-Replica is a new training path on the same /replicas endpoint as video-based training, with train_image_url and voice_name in place of train_video_url. For the best results, the image must resemble a human face, so the model can properly identify and generate a coherent AI human from it. Real photographs, AI-generated portraits, illustrated and stylized human characters, and human-like mascots all qualify.
The flow is designed to feel familiar. An image is uploaded and scored against the qualities a great AI human requires: clear front-facing framing, even lighting, no occlusion, a recognizable human face. When the input falls short, the system returns specific, actionable feedback in real time, and a new Fix with AI button can repair the image inline, present the corrected version, and let the user submit or retry without ever leaving the upload flow. From there, the system synthesizes natural training footage from the still using a motion-controlled video diffusion approach, animating the image into a brief clip that captures the talking, listening, and micro-motion a video camera would have captured, never compromising naturalness. That synthesized clip then feeds into the same Phoenix-4 training pipeline as every other Tavus AI human, which means no parallel pipeline, no separate code path, and no implementation work for builders to support it on their end.

Image-to-Replica is not a replacement for video training. It is a second front door, useful in a different set of circumstances, and each path comes with its own tradeoffs.
Video training, when the conditions are right, is the highest-fidelity path for an AI human modeled after a specific real person. It captures the individual expressiveness of the subject, the way their mouth moves, the angle of their head when they think, the personal quirks of how they show up on camera. When you have access to that person and the conditions to record them well, video is the answer.
Image training is the lowest-friction path, useful when speed, access, or the type of subject makes video impractical. It lets a builder iterate on lighting, framing, and creative direction inside an image before training even begins, in a way a one-take session does not allow. Both paths produce real-time AI humans, and the train time is the same. The choice is about the input, not an output tier.
| Dimension | Video Training | Image Training |
|---|---|---|
| Input | ~30s speaking + ~30s listening video | Single front-facing image, human-like face |
| Setup | On-camera subject, lighting, framing | Upload image, run pre-check, Fix with AI on any failure |
| Voice | Captured from training audio, or paired with a stock or custom voice | Stock voice_name, or paired with a stock or custom voice |
| Subject types | Real people who can sit for a recording | Real photographs, AI-generated portraits, illustrated and stylized human characters, human-like mascots |
| Downstream pipeline | Phoenix-4 | Phoenix-4 (same) |
| CVI integration | Persona | Persona (no special handling) |
| Best for | A specific real person at the highest fidelity | Speed, iteration, prototyping, non-recordable subjects |
Image-to-Replica is available today across the Tavus platform.
/replicas endpoint as video-based training, with train_image_url and voice_name parameters.An AI human is not just a face. It is a perception system that watches and listens. A conversational flow model that knows when to speak and when to wait. An emotional rendering engine that reflects what is happening in real time. A memory that holds the conversation from last week or even a personality that has been shaped over weeks of interaction. The face is just where it all begins.
For a long time, the face has been the slowest part of that build. Layering on intelligence, memory, and personality could not begin until someone had sat down on camera. The hardest part came first. With Image-to-Replica, that first step now takes seconds, which means everything that matters most can begin almost immediately: the perception, the personality, the conversation, the relationship.
Tavus was built to solve the human computing problem, and we see a future where talking to a machine can feel as natural as talking to a friend or a coworker, where AI companions, assistants, and coworkers are commonplace, and where the interface itself feels human. Each release pulls us closer. Phoenix-4 brought emotional presence to rendering, Raven-1 gave AI humans the ability to truly see and hear, and Sparrow-1 gave them human-level timing. In recent paired evaluations of conversational quality, participants preferred Tavus AI humans on six of seven measures of emotional and conversational fidelity, chose Tavus on every head-to-head question asked, and gave Tavus the only positive score among providers on the question of whether they occasionally forgot they were talking to AI at all.
Image-to-Replica is the next step in that work. It removes the last reliably manual step between imagining an AI human and bringing one into the world.
Learn more in our docs.
