
Industry
10+ Best Speech Recognition API Tools [2025]

Written by

Julia Szatar
Key Takeaways
The evolution of speech recognition technology has transformed how applications process and understand human speech. According to Stanford’s AI Index Report, speech recognition accuracy now exceeds 95% in optimal conditions, making these APIs increasingly crucial for modern applications.
As conversational AI platforms become more sophisticated, choosing the right speech recognition API is essential for delivering natural, responsive user experiences.
This comprehensive guide examines the leading speech recognition APIs, evaluating their features, accuracy rates, and specific use cases to help development teams make informed decisions about their speech processing infrastructure.
Speech Recognition APIs transform spoken language into text through sophisticated machine learning models and signal processing techniques. These systems manage various acoustic conditions and speech patterns while converting audio into accurate, usable text.
Modern AI APIs process speech in multiple stages. First, they analyze the audio signal, identifying speech patterns and filtering out background noise. Next, they break down the speech into phonemes, or the basic units of sound in language. Finally, they convert these sound units into text using contextual understanding and language models.
Consider a video conferencing application: when a user speaks, the speech recognition API processes the audio in real-time and converts spoken words into text for features like live captioning or meeting transcription. The system must handle different accents, speaking speeds, and background conditions while maintaining accuracy.
These APIs have evolved beyond simple dictation tools. Contemporary speech recognition systems understand context, identify multiple speakers, and adapt to individual speech patterns. For example, in conversational agentic AI workflows, APIs enable natural interactions by processing speech with minimal latency while maintaining conversation flow.
Development teams integrate speech recognition APIs to add voice capabilities to their tech offerings without building complex speech processing infrastructure. This approach allows applications to focus on their core functionality while leveraging sophisticated speech recognition capabilities through simple API calls.
Speech recognition APIs transform application capabilities by enabling automated speech processing and natural voice interactions. These systems offer several key advantages for modern application development.
Speech recognition APIs enable hands-free interaction with applications, creating more natural and accessible user experiences. Through AI voice API integration, applications can process natural speech in real time, allowing users to interact more intuitively with digital interfaces. Navigation systems, for example, can leverage speech recognition to enable accurate voice command functionality so drivers can maintain focus on the road.
Modern speech recognition systems achieve remarkable accuracy through advanced machine learning models. Enterprise-grade APIs maintain consistent performance across different accents, languages, and acoustic environments. Medical dictation systems, for example, now accurately transcribe complex terminology in various hospital environments.
Speech recognition APIs handle varying workloads efficiently, from single-user applications to enterprise-scale systems. The cloud-based infrastructure manages resource allocation automatically, ensuring consistent performance during usage spikes. Video platforms can process thousands of concurrent streams while maintaining low latency.
By leveraging existing speech recognition infrastructure, development teams avoid building complex speech processing systems from scratch. This approach significantly reduces development time and resource requirements. Teams can focus on core application features while still offering sophisticated voice capabilities.
API-based speech recognition offers predictable pricing models based on actual usage. The pay-as-you-go model ensures businesses only pay for the processing they need, so organizations avoid the substantial costs of developing and maintaining proprietary speech recognition systems.
Leading speech recognition APIs regularly update their models with improved algorithms and expanded language support. Applications automatically benefit from these improvements without requiring significant updates. This continuous evolution ensures systems maintain state-of-the-art performance over time.
Let’s review some key features and performance capabilities to consider when choosing the best speech recognition API for your needs.
Speech recognition performance extends beyond basic accuracy rates. The best AI voice APIs maintain consistent accuracy across various accents, dialects, and acoustic environments. Real-world applications often face challenging conditions—from noisy public spaces to echo-prone conference rooms and diverse accents—making robust performance crucial for user satisfaction. Consider how the API handles background noise, multiple speakers, and industry-specific terminology.
Language support capabilities directly impact an application’s reach and effectiveness. Modern speech recognition systems should handle multiple languages and dialects with the same level of accuracy. Evaluate not just the number of supported languages but also the depth of support for each, including accent recognition and custom vocabulary options.
Some APIs offer language detection features, automatically identifying and switching between languages during processing.
Implementation success depends heavily on integration capabilities and technical support. The API should provide comprehensive documentation, reliable SDKs, and responsive support channels. Consider its authentication methods, rate-limiting policies, and data format options. Conversational AI platforms must integrate with existing systems seamlessly while maintaining security and performance standards.
Enterprise applications demand reliable performance at scale. Evaluate the API’s concurrent processing capabilities, geographic distribution of servers, and load balancing features. Consider how the system handles usage spikes and maintains low latency during peak use periods. The provider’s infrastructure should offer robust failover capabilities and clear uptime guarantees.
Pricing models vary significantly among providers, impacting long-term ROI. Analyze per-minute or per-request costs, volume discounts, and additional feature pricing. Research hidden costs like storage fees or premium support charges. Your chosen solution should offer predictable pricing that aligns with your use patterns and growth projections.
The following solutions are the leading speech recognition platforms, each bringing unique strengths for different use cases and implementation requirements. From real-time processing to batch transcription, these APIs demonstrate the advancing capabilities of modern speech recognition technology.

Tavus brings humanlike, face-to-face conversation into any application through its Conversational Video Interface (CVI). Powered by Tavus human simulation models—Phoenix‑3 for lifelike facial rendering, Raven‑0 for perception, and Sparrow‑0 for natural turn‑taking—CVI processes speech in real time with sub‑second latency and delivers a responsive video presence.
The system particularly excels in video-enabled applications. With high‑quality, real-time video APIs, developers can create experiences that respond to speech with humanlike presence, elevating engagement across onboarding, training, and support.
Tavus supports over 30 languages and adapts to different accents and speaking styles while maintaining consistent performance. The platform’s enterprise focus ensures scalability and security for high‑volume, mission‑critical applications.
Features:
Pricing:
Transform your applications with Tavus CVI’s advanced speech recognition and real-time video presence, and join leading companies already leveraging Tavus’ cutting-edge technology.

Google’s Speech-to-Text API leverages machine learning models to deliver speech recognition across diverse scenarios. The platform processes both real-time streams and pre-recorded audio, adapting to various audio conditions and speaking styles. The API automatically identifies and filters background noise, and recent updates enhanced speaker diarization capabilities to handle multi-speaker scenarios.

Features:
Pricing:

Microsoft’s Azure Speech Service combines speech recognition capabilities with Azure ecosystem integration. The platform offers features for both real-time and batch processing scenarios, with particular strength in enterprise applications. The service integrates with other Azure services for workflow automation and analytics.

Features:
Pricing:
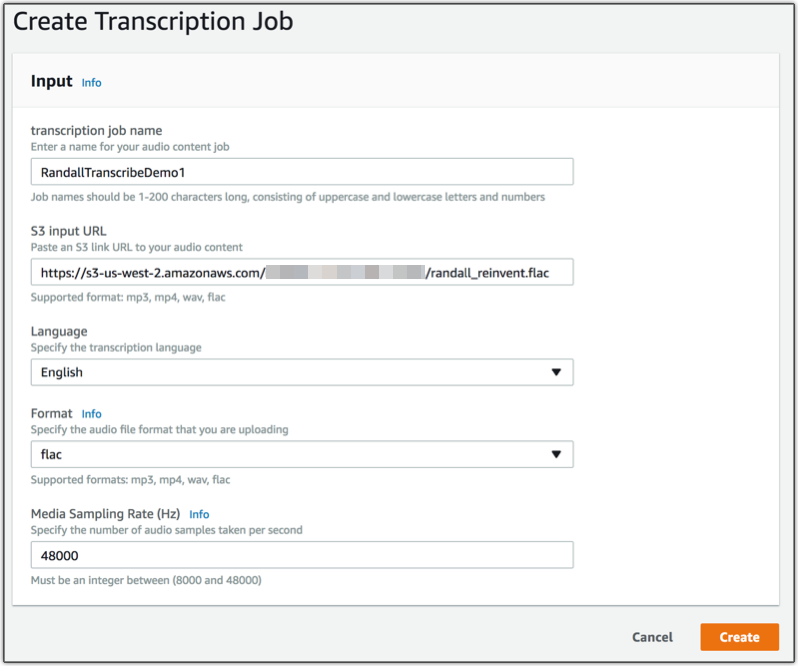
Amazon’s Transcribe service delivers enterprise-grade speech recognition through its cloud infrastructure. The platform processes both streaming and batch audio, with specialized features for content production and analytics applications.
Features:
Pricing:

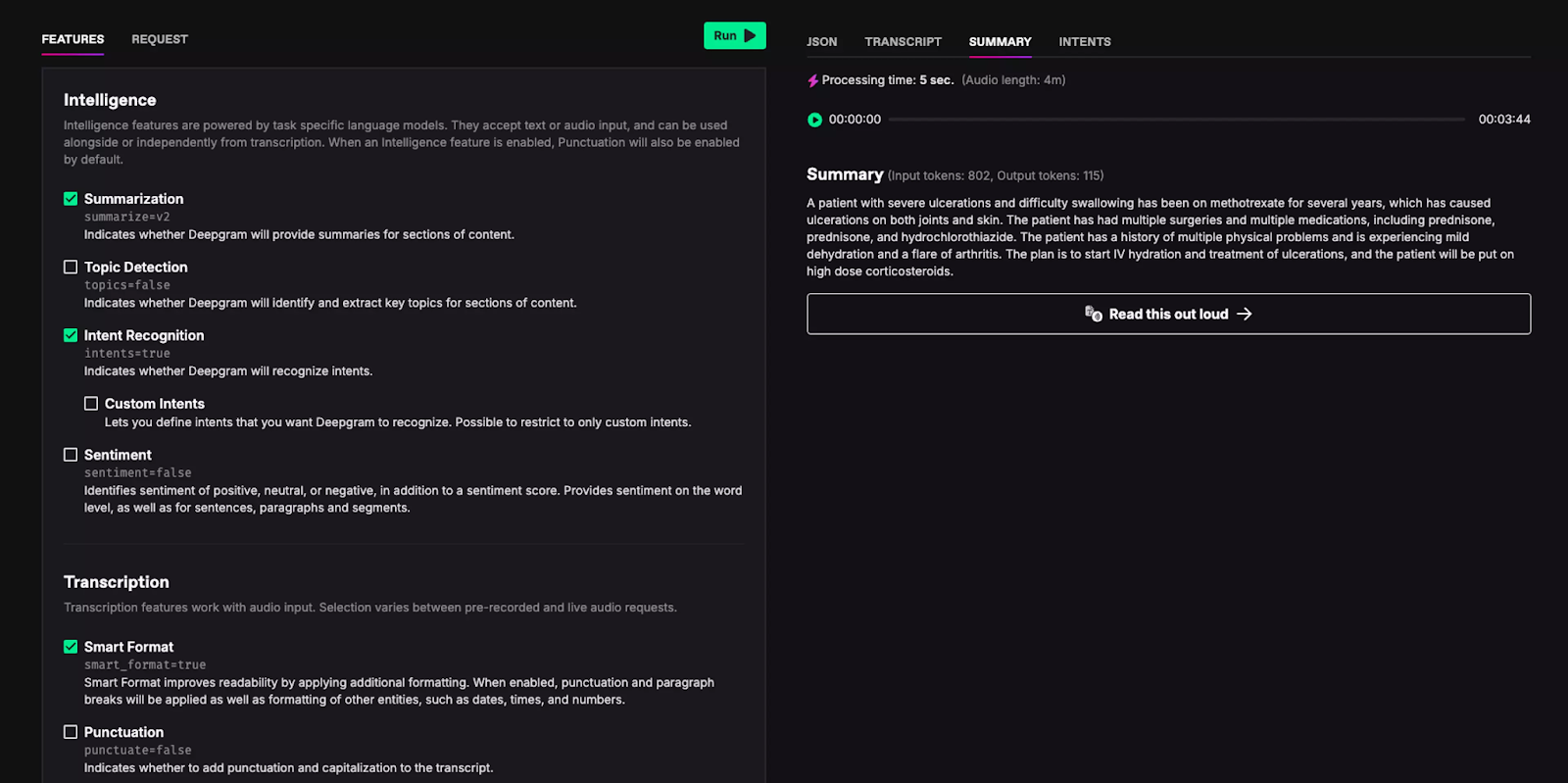
Deepgram offers AI speech recognition for specialized use cases. The platform uses a deep learning approach for processing audio in various conditions and domain-specific applications.
It offers custom model training for industry-specific terminology, accents, and acoustic environments. The platform includes real-time processing capabilities and API integration documentation.
Features:
Pricing:

OpenAI’s Whisper API converts open-source speech recognition technology into a production service. The platform offers multilingual capabilities across diverse audio conditions, including accented speech and challenging audio environments.

Features:
Pricing:

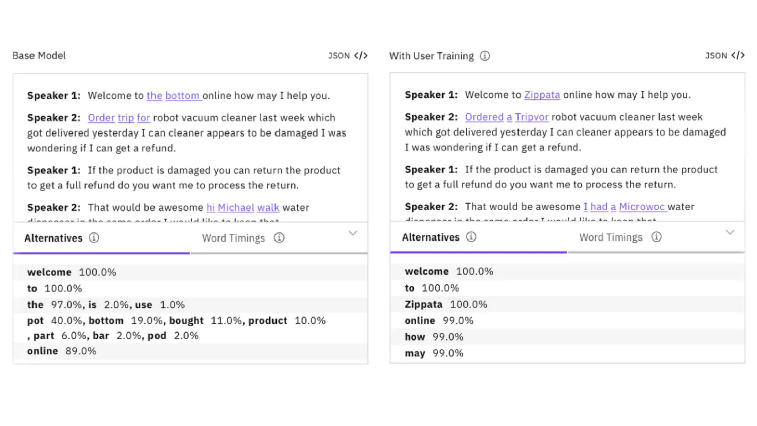
IBM’s Watson Speech-to-Text service combines enterprise reliability with advanced customization options. The platform processes both real-time and batch audio across diverse industry applications. The platform processes specialized vocabulary and industry terminology through configurable models for highly technical industries.
Features:
Pricing:

AssemblyAI delivers modern speech recognition capabilities through their API. The platform specializes in content analysis and understanding, offering features beyond basic transcription. AssemblyAI’s model also identifies key phrases, entities, and action items for content production and analysis workflow use cases.
Features:
Pricing:

Rev’s speech recognition API processes English language content using transcription technology and sentiment analysis. The platform also includes API integration and handles various audio quality levels.
Features:
Pricing:

Speechmatics offers autonomous speech recognition technology with advanced language understanding capabilities. The platform processes multiple languages and dialects while adapting to various audio conditions and speaking styles.

Features:
Pricing:
Modern speech recognition APIs enable diverse applications across industries, transforming how organizations handle voice data and user interactions. From content creation to accessibility features, these systems drive innovation in multiple domains. Let’s dive into the most common use-cases for speech recognition APIs.
Speech recognition APIs revolutionize content production workflows through their automated transcription and processing capabilities. High-quality AI video APIs like Tavus combine speech recognition with video generation, allowing developers to offer personalized video content generation at scale.
Whether your end users want to transcribe podcasts, generate closed captions, or create multilingual content, speech recognition technology enables fast and easy content creation.
Media organizations leverage speech recognition for automated subtitle generation and content indexing. The technology processes hours of content automatically, maintaining accuracy while significantly reducing production time. Modern APIs handle multiple speakers, background noise, and specialized terminology, making them valuable for both live and recorded content.
Conversational AI technology allows organizations to build sophisticated voice interfaces for customer interaction. Speech recognition enables natural language understanding in real-time, allowing systems to process and respond to user queries efficiently. Tavus enhances these interactions by generating video responses with AI lip sync technology, creating more engaging user experiences.
Speech recognition technologies make digital content more accessible to diverse user groups. Applications include:
These capabilities ensure broader access to digital services while improving user experience for all.
We have answers to common questions about speech recognition APIs.
Modern speech recognition APIs achieve accuracy rates exceeding 95% in optimal conditions. Tavus’ platform maintains exceptional accuracy through advanced noise cancellation and speaker adaptation.
However, performance can vary based on factors like audio quality, background noise, and accent complexity. Enterprise solutions typically offer custom model training to enhance accuracy for specific use cases.
Leading platforms support numerous languages and dialects. Tavus supports over 30 languages with natural accent adaptation capabilities. Most enterprise APIs handle major world languages, while specialized providers may offer deeper support for specific regions or dialects.
Support quality can vary by language, with some platforms offering more advanced features for widely-spoken languages.
Enterprise-grade speech recognition APIs implement robust security measures. Tavus maintains strict data protection protocols, including encryption, access controls, and compliance with major regulatory frameworks. Developers should evaluate providers’ data-handling practices, storage locations, and compliance certifications based on their industry’s specific requirements.
For applications requiring advanced speech recognition with real-time, face-to-face interaction, Tavus provides a complete solution through its Conversational Video Interface (CVI). The platform combines precise audio with real-time video presence, making it particularly effective for developers building interactive, video-enabled applications.
Consider factors like accuracy requirements, language support, integration needs, and budget when making your selection.
Speech recognition technology continues to evolve, enabling developers to build increasingly sophisticated voice-enabled applications. As development teams face growing pressure to deliver AI tech that generates natural, efficient user interactions, choosing the right speech recognition API is crucial for successful integration of speech recognition tools.
Tavus empowers developers with advanced speech recognition capabilities through its Conversational Video Interface (CVI). While end users can leverage this technology for personalized video content and customer engagement, developers benefit from its efficient implementation, robust documentation, and flexible integration options.
Tavus CVI combines speech processing with video generation in a single, unified solution, eliminating the complications of managing multiple services and ensuring consistent performance. This integration allows developers to focus on building innovative applications rather than managing complex speech recognition API infrastructure.
