
Research
Sparrow-1: Human-Level Conversational Timing in Real-Time Voice

Written by

Brian Johnson
Sparrow-1 is a specialized, multilingual audio model for real-time conversational flow and floor transfer. It predicts when a system should listen, wait, or speak, enabling response timing that mirrors human conversation rather than simply responding as fast as possible.
Despite major advances in LLMs and TTS, conversational AI still lacks reliable human-level timing. Traditional voice systems wait for silence, then respond. Sparrow-1 instead models conversational timing continuously. This allows it to respond quickly, even instantaneously when the speaker is clearly done, all while deliberately waiting when they’re not.
The difference is subtle but transformative: Sparrow-1 doesn't just respond as fast as possible. It responds at the moment a human listener would.
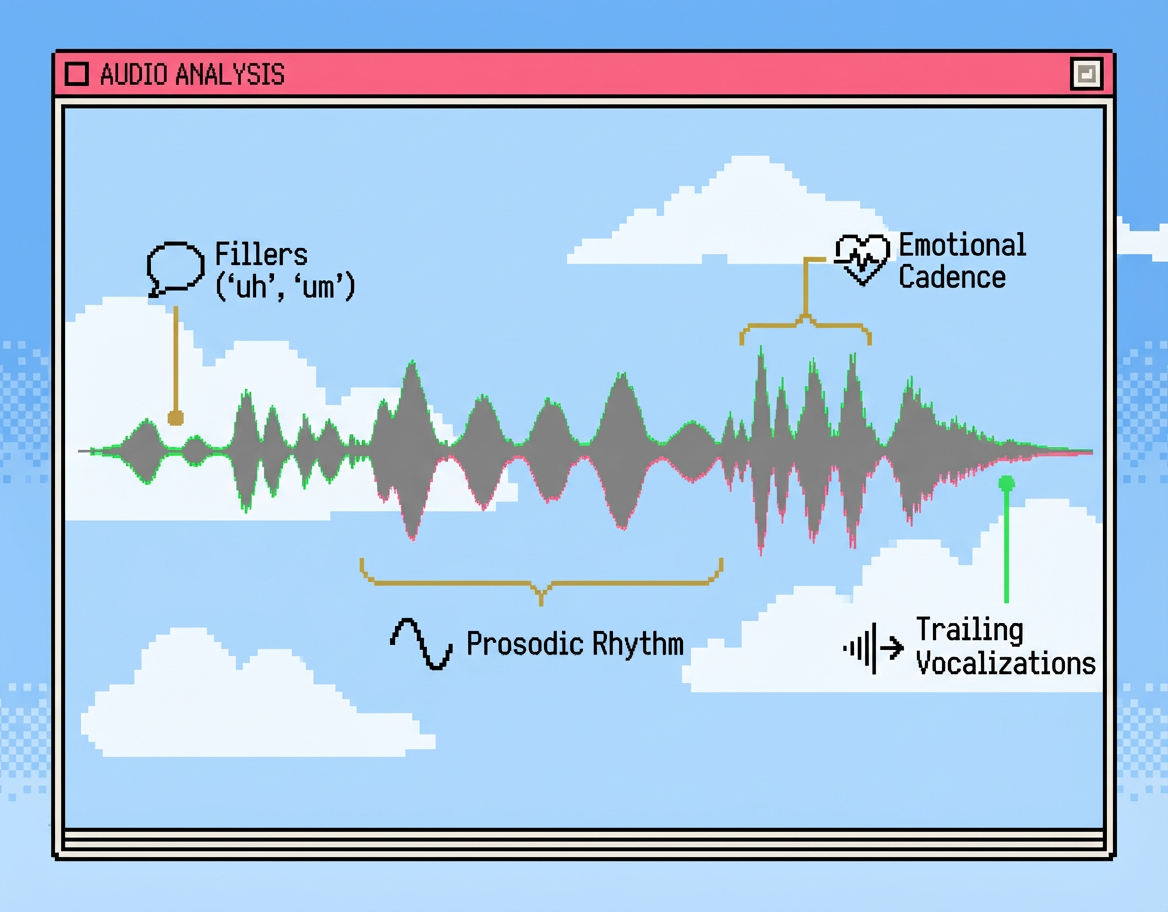
Conversation is not just an exchange of words. It is a real-time coordination task where participants continuously anticipate when to respond, drawing on rhythm, hesitation, intonation, and meaning at the same time. Sparrow-1 models this coordination directly, aligning its behavior with the timing patterns humans use subconsciously during dialogue.
Research in conversation analysis and psycholinguistics has identified several key categories of signals that govern conversational-flow:
When you talk to an AI with a human voice, you expect human timing. When timing breaks down, you notice immediately. Delayed responses, premature interruptions, and awkward pauses shatter the rhythm of natural dialogue.
Today’s voice AI sounds increasingly human, yet still feels mechanical in conversation. Systems on platforms like ChatGPT, Claude, and Grok decide when to speak using endpoint detection, waiting for silence thresholds before responding. They react to the absence of sound rather than conversational intent, leading to missed hesitation cues and poorly timed responses. The voice sounds real, but the interaction does not.
Human-level conversation requires more:
Most systems fall short since they treat conversational-flow as an afterthought, a threshold to tune rather than a problem to model.
Sparrow-1 takes a different approach: it models humanlike floor transfer with intent, timing, and tone, ensuring that conversational timing matches the realism of the voice delivering it.
Sparrow-1 is a conversational flow control model built for real-time conversational video in Tavus’s Conversational Video Interface. It treats timing as a first-class modeling problem rather than an artifact of endpoint detection, extending Sparrow-0 with a more capable architecture and richer supervision.
Most existing turn-taking systems are built around endpoint detection. They wait for speech to stop, apply silence thresholds, and then trigger a response. This reactive design introduces latency, misinterprets hesitation as turn completion, and fails to support natural conversational behaviors such as backchanneling, overlap, and interruption. Silence is treated as a proxy for intent, even though the absence of speech does not reliably signal that a speaker has yielded the conversational floor.
Sparrow-1 takes a different approach. Instead of asking whether speech has ended, it models who owns the conversational floor at every moment, allowing it to anticipate turn transitions rather than react to them.
Sparrow-1 is not a general language model or even strictly a turn-taking model. It is a timing and control system that governs when a conversational system should speak, wait, or get out of the way: a conversational-flow model
This distinction matters because conversational timing is not handled cleanly by most real-time voice architectures. Today, two dominant approaches exist:
End-to-end speech-to-speech models handle timing implicitly but are expensive, opaque, and difficult to control or customize. They achieve fluency by tightly coupling perception, reasoning, and generation, but sacrifice efficiency and controllability in the process.
Modular pipelines (ASR → LLM → TTS) are flexible and scalable but suffer from a coordination problem: timing decisions fall between components, with no dedicated mechanism for deciding when the system should speak.
Sparrow-1 fills this gap. By explicitly modeling conversational floor transfer as a standalone timing and control layer, it brings human-level conversational-flow to modular pipelines, preserving their flexibility while restoring the conversational feel users expect.
Conversational-flow systems are often evaluated on clean endpoints and average latency, but these metrics are not representative of the true human dance, and miss the failures that matter most in real conversation: cutting users off, waiting too long, or behaving inconsistently during hesitation.
To evaluate these cases, we benchmarked Sparrow-1 against representative industry approaches using 28 challenging real world audio samples of real conversations designed to expose hesitation, overlap, and ambiguous turn endings, rather than clean silence.
Each system was evaluated on the same set of 28 real-world conversational samples. Performance was measured across response latency, correct floor transfer, and interruptions. Correct floor transfer was measured using precision and recall within a 400ms grace window that reflects human conversational tolerance.
Correct floor transfer is quantified using precision and recall, with a 400ms grace window that reflects the tolerance humans naturally allow in conversation. Detections occurring within 400ms before a speaker finishes are treated as correct, while earlier responses are classified as interruptions. Precision captures how often a system avoids cutting users off, while recall measures how reliably it responds when a turn is actually complete.
Across existing approaches, the benchmark exposes a consistent speed and correctness tradeoff. Conservative systems minimize interruptions by waiting for extended silence, but impose multi-second delays that feel unnatural in dialogue. More aggressive systems reduce latency by lowering detection thresholds, but interrupt users frequently. In practice, systems are forced to choose between being slow or being wrong.
These results show that this tradeoff is not inherent to conversation, but a consequence of endpoint-based turn-taking design.
Existing systems force a choice between responsiveness and correctness:
Sparrow-1 avoids this compromise by responding quickly when a turn is complete and waiting when the user is still speaking, achieving both speed and correctness.
This performance reflects a fundamentally different approach. Sparrow-1 treats conversational flow as continuous, frame-level floor ownership prediction, aligning its behavior with human conversational timing.
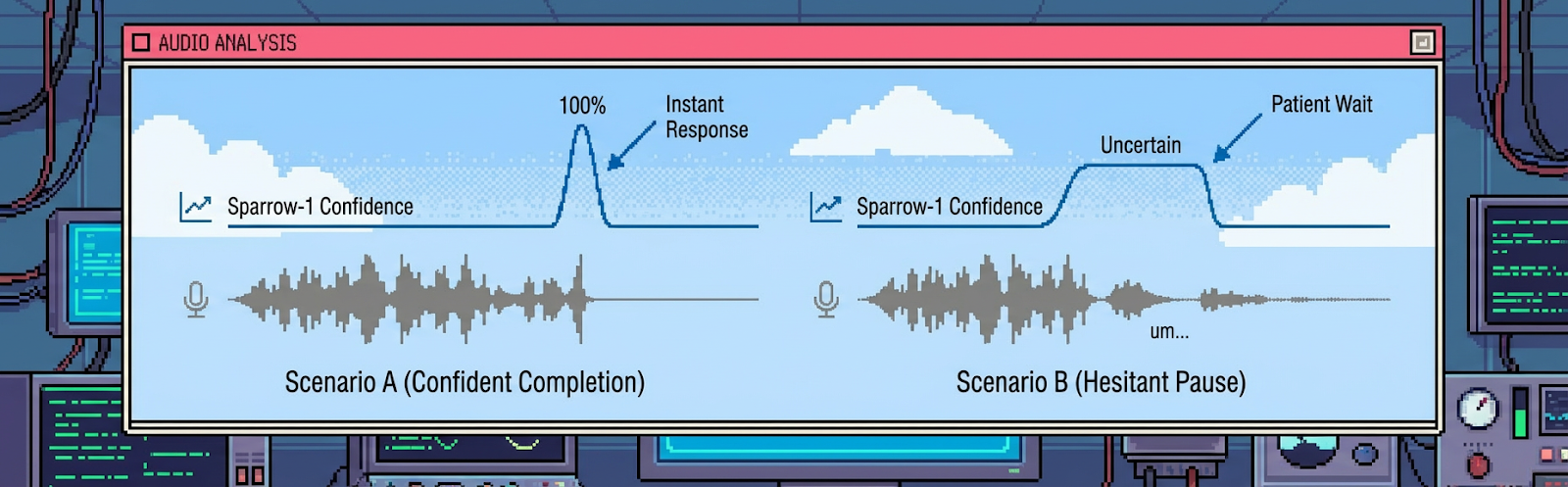
Human conversation optimizes for appropriateness, not speed. People respond quickly when intent is clear and wait when meaning is uncertain.
Because Sparrow-1 models conversational certainty directly, its response latency is dynamic. It responds in under 100ms when confident and waits during hesitation or trailing speech, typically producing response times of 200 to 500ms without multi-second delays.
This ability to be simultaneously fast and patient creates the perception of zero-latency conversation. The system responds not as quickly as possible, but at the moment it should.
These design choices manifest as concrete runtime behaviors that govern how Sparrow-1 adapts, interrupts, and listens during live conversation. At runtime, turn-taking emerges from continuous speaker adaptation, interruption-aware control, and audio-native perception rather than fixed rules or thresholds. The result is behavior that closely matches how humans manage conversational flow in practice.
Sparrow-1 behaves as a meta in-context learner, adapting to individual speaking patterns continuously as a conversation unfolds. Using a recurrent architecture, each 40ms frame updates internal state that encodes prosody, pacing, historical turn timing, and response latency preferences.
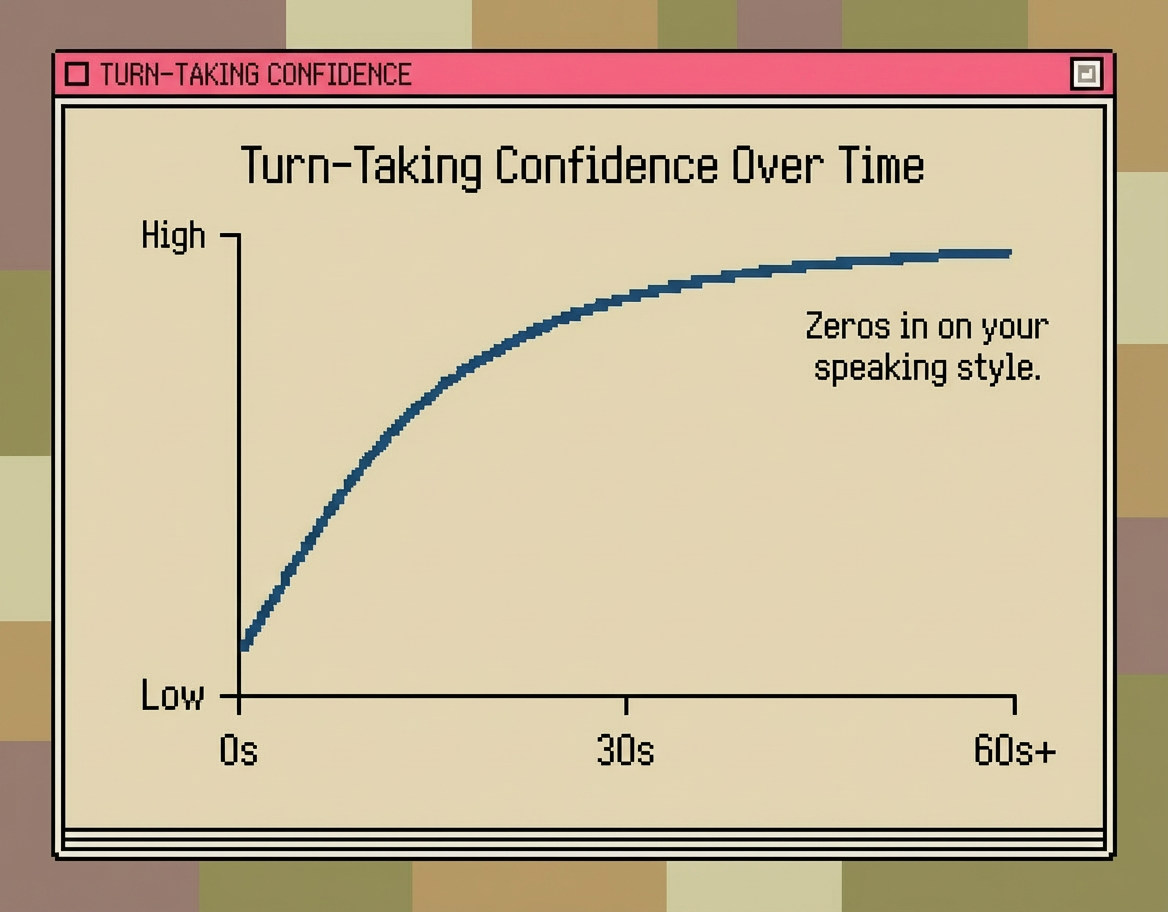
Early in a conversation, the model operates with higher uncertainty. As evidence accumulates, predictions sharpen around user-specific patterns, producing progressive synchronization without explicit calibration.
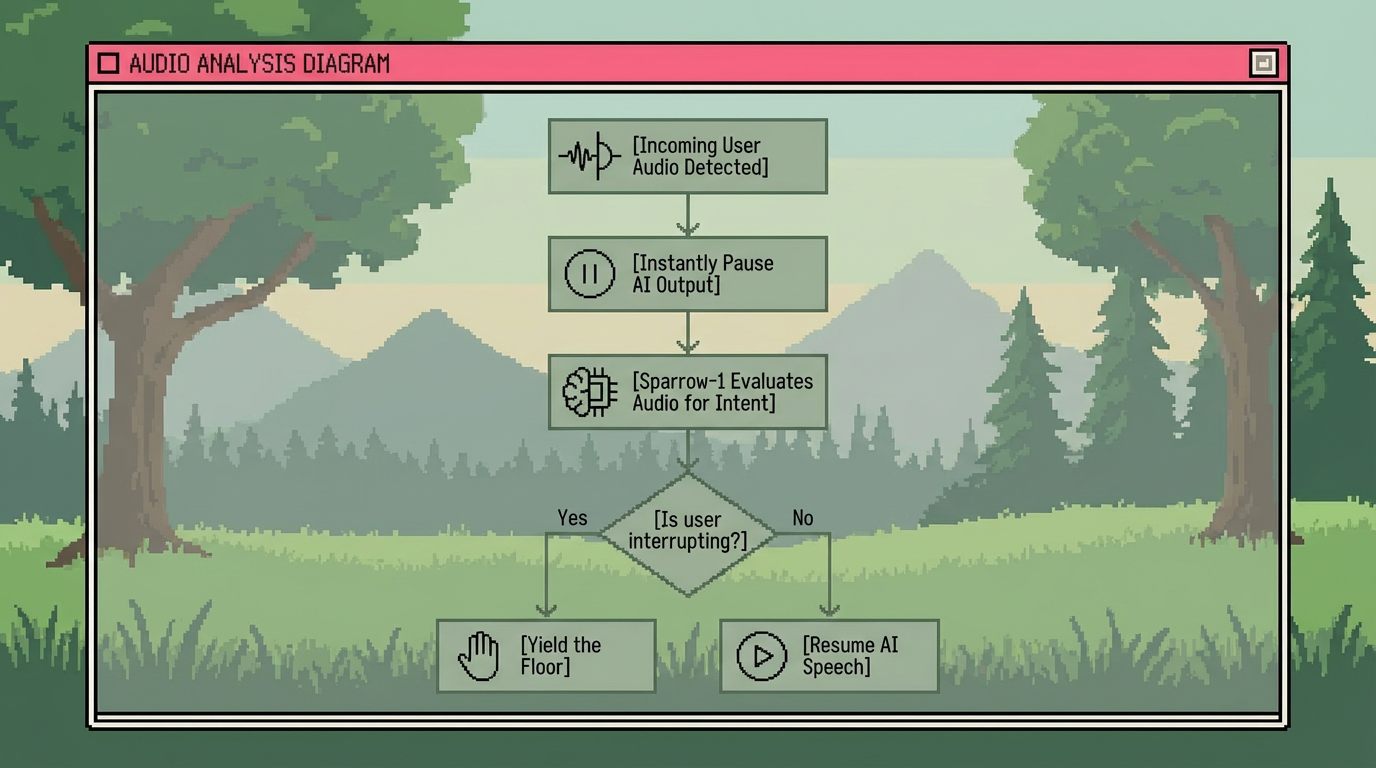
Interruptions are treated as first-class conversational signals. Incoming speech during system output immediately pauses playback while the model continues evaluating floor ownership. If confidence rises, Sparrow-1 yields the turn. If not, it resumes speaking. This process distinguishes intentional interruptions from incidental overlap within tens of milliseconds without introducing delay.
Sparrow-1 models conversational intent using acoustic and temporal cues that extend beyond lexical content: interpreting not just what is said, but how it is said:
By incorporating these paralinguistic signals into its floor predictions, Sparrow-1 aligns with how humans naturally infer attention, hesitation, and intent during conversation: resulting in listening that feels responsive rather than reactive.
We built Sparrow-1 as part of a broader mission: teaching machines to participate in human conversation. Our Conversational Video Interface (CVI) powers AI experiences that look, sound, and interact like real people: and poor timing breaks that illusion faster than almost anything else.
In conversational AI, the uncanny valley is rarely about what the AI says. It's about when it says it. Responses that arrive too early feel rude; too late, artificial. In conversational video, these errors are amplified, reminding users they're speaking to a system rather than a partner.
We use Sparrow-1 to solve this at the level it must be solved: as a first-class timing and control system. By modeling conversational uncertainty directly and responding with human-like precision, it enables interactions that feel attentive, patient, and natural.
Sparrow-1 is now available to GA across the Tavus APIs and platform, and already powers conversational experiences in the Tavus PALs and enterprise deployments.
Try the demo at tavus.io and learn more in our docs.
