
All Posts
Developer
The (Tavus) Hackathon Cookbook

Written by

Alex Behrens
So you want to build a Conversational Video Interface? You’re in good company, startups like Mercor and Delphi and Fortune 500s alike are leveraging Tavus APIs to build the future of AI interaction.
If you haven’t yet, sign up for a Tavus account here or find a Tavus team member to get free credits and start building right away. Once the promo is applied, you’ll see the free conversational video minutes and replica generations added to your account, these work for both new and existing users. You can double-check your billing page to confirm and track usage anytime via the “invoice history” link.
So how does this actually work? At the core of the Tavus offering is something we call CVI, or the Conversational Video Interface. You can think of it like a live video portal into an AI agent. It feels like a real video call, but the other side is a hyperrealistic avatar powered by your prompts, logic, and data.
That avatar is called a Replica. Replicas are digital twins trained on real people using just two minutes of source video. Once submitted, the system kicks off a heavy inference process to generate a 3D Gaussian diffusion model of you! This takes a few hours, but the result is a fully rendered and controllable AI version of that person, ready to plug into anything you want. You can create your own Replicas or use Tavus’s library of 100+ prebuilt Replicas ready to test with right away.
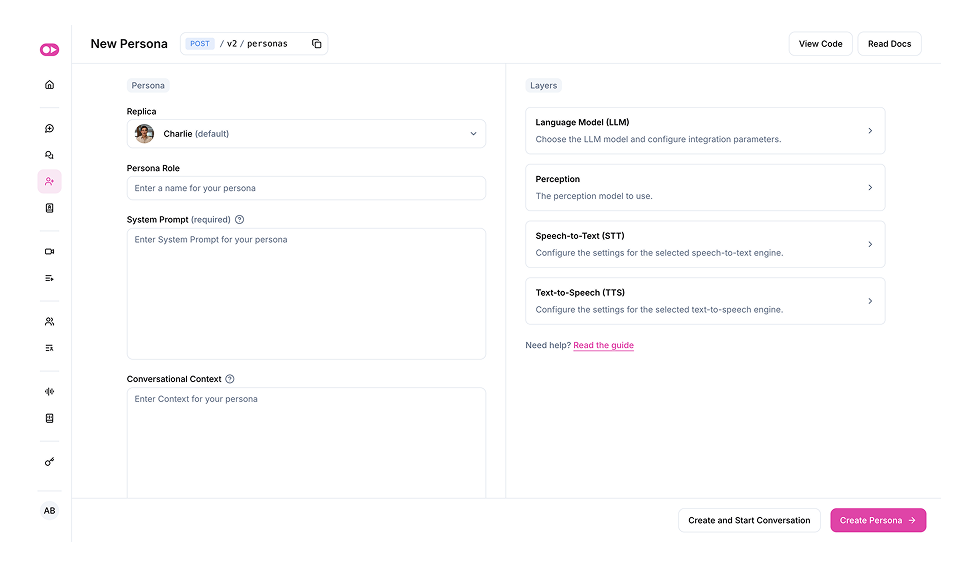
Once you have your Replica ready you’ll create a Persona, which controls how your Replica behaves in conversation. This includes the system prompt that defines tone and behavior, the voice model it uses, and the LLM that controls the conversation. You can also configure tool calling, memory settings (context dump, RAG, etc), and more.
Each Persona is also made up of layers that define how it processes and responds during a conversation. You can alter the base LLM for generating replies, the perception layer for interpreting visual signals, the Speech-to-Text (STT) engine for transcribing the user’s voice, and the Text-to-Speech (TTS) engine to swap out the Replica’s voice. These settings give you full control over the brain, eyes, ears, and voice of your Persona.
Once your Replica and Persona are set up, the next step is to initiate a live session using the Create Conversation API. This API call establishes a WebRTC video room where your AI-powered Replica, guided by its Persona, interacts with users in real time.
You can customize each conversation by specifying parameters such as the unique Replica and Persona IDs, and optional settings like a custom greeting, conversational context, language preferences (Tavus supports 30+), and call duration settings. Upon creation, the API returns a conversation_url that can be embedded into your application or accessed directly, allowing users to engage in a dynamic, face-to-face interaction with the AI agent.

Speaking of embedding, that part is dead simple. You can choose between Daily (default) or LiveKit as your WebRTC provider. Both support flexible open source UI layers, so you can style and control the look and behavior however you want. Use whichever one fits your build best.
The entire system is API-first and dev-friendly. You can leverage Tavus with TypeScript, JavaScript, Python, or whatever stack you’re working in. Everything from spinning up conversations to creating Replicas and Personas is handled through clean, well-documented endpoints.
Now that you’re briefed, you can head over to the Create Conversation tab in the Developer Portal to start testing real-time conversations, prompts, and grab your API keys to so you can start embedding your first agent in just a few minutes.
.gif)
To build with Tavus, it helps to know how our model stack works. CVI runs on a modular system that handles rendering, perception, timing, and language to deliver lifelike AI video agents.
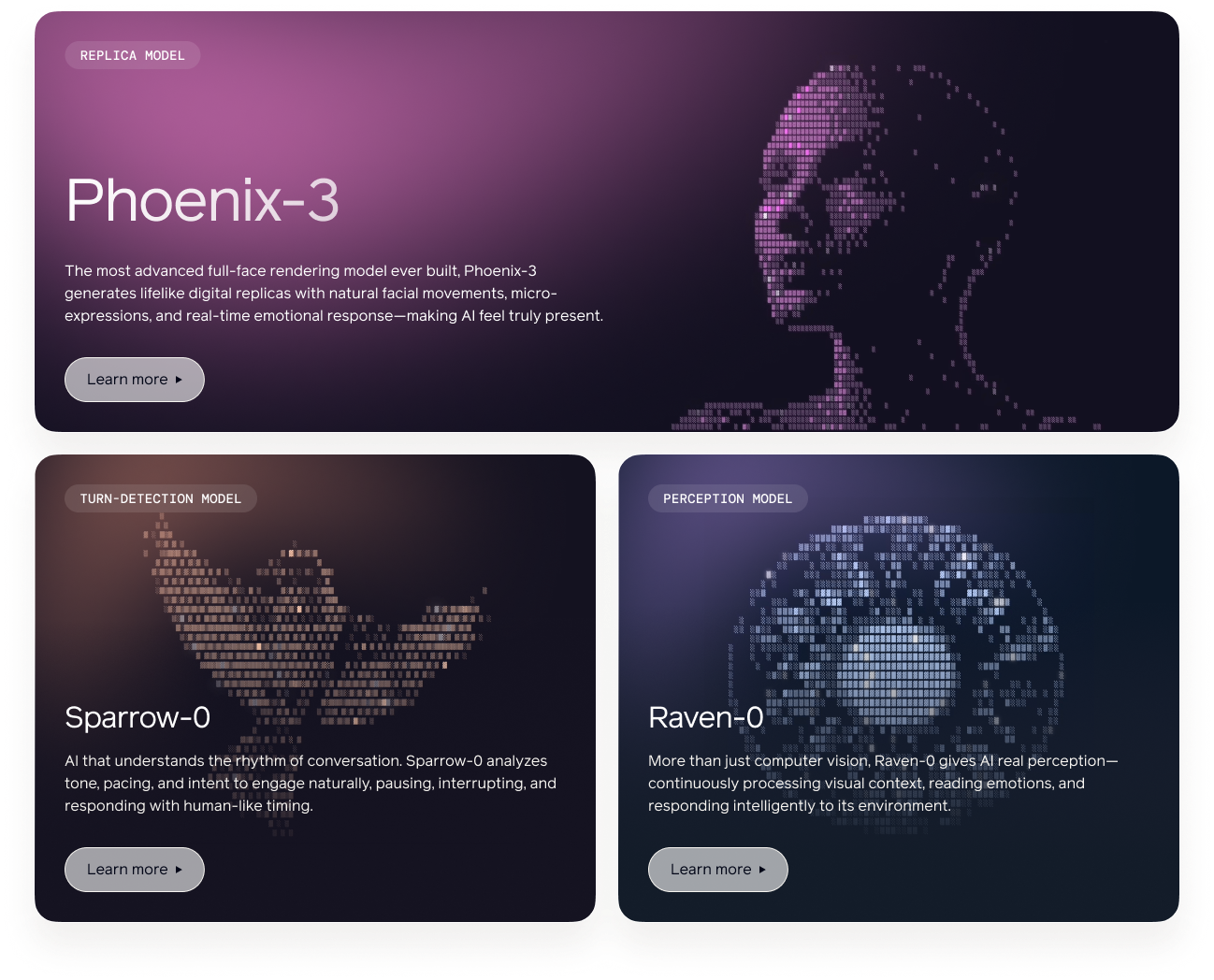
We built three core models in-house to power the experience:
We also plug in best-in-class external models for the rest:
Each of these can be configured per Persona, giving you full control over the intelligence, tone, and rhythm of your Replica.
There are a few key UI and UX patterns that make Conversational Video Interfaces feel intuitive and polished. These are based on what we've seen work best across projects using Tavus. Our examples repo gives you everything you need to get started with CVI, from a barebones React framework to fully fleshed out projects.
As mentioned above, the conversation UI is powered by a WebRTC provider. By default, Tavus spins up a prebuilt Daily room with all the core UI components, perfect for testing and quick demos. For production, you’ll want to build your own experience using LiveKit or customize Daily's open source UI.
Start with our embedding guide to get the basics, then dive into the Daily or LiveKit docs for full control.
Here’s the core flow:
Other concepts:
Tavus gives you full control over how your agents behave, adapt, and react during live sessions. You can push updates to context, inject user inputs, handle real-time events, and output structured artifacts based on both what the user says and what the Replica sees. This is achieved via the persona layer and the conversation layer.
You can also record sessions, transcribe audio, and use those outputs downstream for training data, analytics, or follow-up workflows.
Interaction Types (see all)
Observable Events
Tools and Function Calling
You can give your Persona access to external tools by defining function calls the LLM can trigger during a conversation. These tools let the agent go beyond text and take real action, like querying APIs, updating databases, or triggering workflows.
Example use cases:
Tools are passed in via the Persona config under layers.llm.tools, and can be configured with full JSON schema validation. During the conversation, if the LLM decides to use a tool, a conversation.tool_call event is emitted. This contains the tool name, arguments as a JSON string, the utterance that triggered the call, and the conversation and inference IDs letting you listen for tool calls in real time and route them however your app needs.
Perception with Raven
Raven-0 is the perception model that gives your Replica real-time visual awareness. It analyzes webcam and screen share inputs to understand user behavior, emotions, and context, enabling more adaptive, responsive conversations.
Key capabilities include:
Prompting defines your Replica’s behavior. It instructs the LLM on its role, tone, and boundaries. Without clear prompts, responses can be inconsistent. With well-structured prompts, you can achieve precise and reliable interactions.
Best Practices
This format is ideal for long-form prompting inside a Persona, where you want control, tone consistency, and clear safety boundaries.
Real-Time Updates
You can also adjust prompts live during a session using the Overwrite Context Interaction. This lets you steer conversations dynamically, ideal for branching flows, escalation logic, or user-specific tailoring.
Good prompting is like good directing. Clear roles, consistent tone, and defined limits lead to better, safer interactions.
You’ve got the tools. Replicas. Personas. Real-time control. Visual perception. Smart prompting. But all of it leads to one core idea... why face-to-face?
Because it changes how people engage.
We don’t just process words. We respond to presence. Faces carry tone, emotion, and trust in a way no text or audio can fully replicate.
When you start with presence, not just prompts, you can create something special. Give your AI a face, a voice, and personality. Because when someone meets your agent’s gaze, conversations become real. Now let’s bring your AI to life with Tavus.
